
준비 및 정리
주니어 개발자를 위한 취업 정보
JAVA와 JAVAScript의 차이
자바와 자바스크립트의 차이는 객체 지향 언어와 스크립트 언어의 차이로 볼 수 있다.
| 자바 | 자바스크립트 |
|---|---|
| 객체 지향 언어 | (객체지향) 스크립트 언어 |
| 클래스 기반 객체 | 프로토타입 기반 객체 => 동적 상속 제공 |
| Explicit type binding = 명시적으로 변수 타입을 정함 | Dynamic type binding = 동적으로 변수 타입이 정해짐 |
| 강한 Type checking | 느슨한 Type checking |
| 범용 프로그래밍 언어 | 웹 클라이언트용 스크립트 언어 (Node.js를 통해 서버측에서도 개발 가능해짐) |
| 컴파일 과정을 거침 (소스코드 => 바이트코드) | 인터프리터 언어 (컴파일 과정이 없음) |
| 서버 등 모든 프로그램 제작에 사용 | HTML의 동적 웹 서비스 개발을 위해 사용 |
XML과 JSON
XML
eXtensible Markup Language의 약자이다. 기본적으로 XML은 HTML의 구조와 매우 유사한데, HTML의 경우 태그가 사전정의 된 것에 비해 XML은 태그를 사용자가 지정 가능하다.
- HTML은 보여주기 위한 언어이고, XML은 데이터 전달 및 저장을 위한 언어
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
JSON
JavaScript Object Notation의 약자이다.
- XML과 동일하게 데이터 전달 및 저장을 위한 양식이다.
{"widget": {
"debug": "on",
"window": {
"title": "Hello world!",
"name": "main_window",
"width": 500,
"height": 500
},
"image": {
"width": 500,
"height": 500,
"src": "./Hello.jpg"
}
}}
공통점
- 데이터 저장 및 전달을 위해 고안됨
- 사람이 쉽게 읽을 수 있는 형태 (Self describing)
- 계층적인 데이터 구조 (Hierarchical)
- 프로그래밍 언어에 의해 쉽게 파싱
- XMLHttpRequest 객체를 통해 서버로부터 데이터 전송받을 수 있음
차이점
- JSON은 종료 태그 사용 안함
- JSON의 구문이 XML보다 짧음
- JSON 데이터를 XML 데이터 보다 빨리 읽고 쓸 수 있음
- XML은 배열 사용 불가, JSON은 가능
- XML은 따로 XML파서가 필요하지만, JSON은 자바스크립트 표준 함수 eval() 함수로 파싱 가능
- XML은 무결성 검증이 되는 반면, JSON은 무결성을 사용자가 직접 검증해야함
AJAX
Asynchronous JavaScript and XML의 약자로, 빠르게 동작하는 동적 웹 페이지를 만들기 위한 개발 기법의 하나
- 비동기적으로 서버와 브라우저가 데이터를 주고 받는 네트워크 통신 방식
- 자바스크립트로 통신을 하고 XML(JSON)으로 데이터를 주고 받는다는 말
- 웹페이지의 일부만 다시 갱신 가능
- 백그라운드에서 서버와 통신하여 결과를 웹 페이지 일부분에만 표시 가능
- JSOM, XML, HTML, 텍스트 등 다양한 형태의 데이터를 주고 받을 수 있음
AJAX 장점
- 웹페이지 전체 로딩 없이도 일부분만 갱신 가능
- 웹페이지 로드 후 서버에 데이터 요청 가능
- 백그라운드에서 서버로 데이터 보낼 수 있음
AJAX 단점
- 클라이언트가 서버에 요청하는 풀링 방식이라, 서버 푸시 방식 같은 실시간 서비스는 만들 수 없음
- 바이너리 데이터롤 보내거나 받을 수 없음
- AJAX 스크립트가 포함된 서버에게만 AJAX 요청을 보낼 수 있음
- 클라이언트 PC로 AJAX 요청을 보낼 수 없음
AJAX 프레임워크
- Prototype
- dojo
- jQuery
Daemon
- 특정 서비스를 위해 백그라운드 상태에서 계속 실행되는 서버 프로세스
- 리눅스 시스템이 처음 가동될 때 실행되는 백그라운 프로세스의 일종
- 사용자의 요청을 기다리다가 요청이 발생하면 적절히 대응하는 리스너 방식
- 메모리에 상주하면서 특정 요청이 오면 즉시 대응 가능하도록 대기중인 프로세스
- 데몬 프로그램 명령어는 d로 끝남
- 웹서버는 서비스 요청이 매우 빈번히 일어나기 때문에
httpd와 같은 웹서버 데몬은 standalone 방식으로 실행됨 - dns 데몬 등
Standalone 데몬
- 독립적으로 수행되며 서비스 요청에 응답하기 위해 항시 메모리에 상주
Super 데몬
- inetd라고 하는 특별한 데몬에 의해 간접적으로 실행되는 데몬
- inetd에 요청이 들어오면 inetd는 해당하는 데몬을 메모리에 올리고 요청 처리
C++
Virtual
상속에서 Virtual
Virtual 파괴자
Volatile
Volatile이 명시되면 외부적인 요인으로부터 언제든지 그 값이 바뀔 수 있다는 걸 명시해준다. 이는 컴파일러의 최적화를 막아준다. 해당 변수는 레지스터에 로드된 값을 쓰지 않고 메인 메모리의 값을 읽는다.
volatile int a = 0;
a = 1;
a = 2;
a = 3;
일 경우 아무런 명시가 없을 경우 컴파일러는 a = 1;, a = 2; 코드를 없애게 되는데, 만약 a 앞에 volatile이라는 키워드가 면시된다면 이런 컴파일러의 최적화를 막아줘서 모두 실행되는 효과를 볼 수 있다. 아래 경우에 유용하다.
- MMIO (Memory-Mapped I/O) : 어떤 주소에 값을 쓰는 행위가 해당 하드웨어 레지스트리에 값을 써 특정 명령을 전달하는 것이라면 위와 같은 최적화가 일어나서는 안된다.
- 멀티 스레드 환경 : 여러개의 스레드가 돌아가는 환경에서 위 a 변수 값은 a = 1, a = 2, a = 3이 실행되는 매 순간 바뀔 수 있다.
스마트 포인터
일반 포인터와 같은 행동을 하지만 속은 다른 Proxy 객체이다
장점
- 메모리 자동 해제 : delete를 명시적으로 호출하지 않아도 자동으로 메모리를 해제해준다.
- 자동 초기화 : NULL로 초기화해주지 않아도 Default 생성자가 자동으로 NULL로 초기화해준다.
- Dangling 포인터 : 이미 삭제된 객체를 가리키는 포인터를 Dangling 포인터라 하는데 이에 대해 해결책 제시
종류
C++11 부터 적용
-
shared_ptr
shared_ptr<Type> smartPtr (new Type);참조 카운트가 0이 되는 순간 메모리 해제된다. 참조 카운트는 해당 변수가 참조될 때 마다 1씩 늘어나고, 코드 블럭이 끝나거나 함수가 종료되면 0이 된 다음 메모리가 해제된다.
-
unique_ptr
unique_ptr<Type> smartPtr (new Type);하나의 참조만 허용하는 포인터.
-
weak_ptr
weak_ptr<Type> smartPtr (new Type);shared_ptr과 함께 사용되어, shared_ptr객체를 weak_ptr로 참조해도 참조 카운트가 증가하지 않는다. shared_ptr끼리 상호 참조되어 객체가 삭제되지 않는 상황을 차단하기위해 사용한다.
Final Class
class Name final {
...;
}
다른 클래스가 해당 클래스를 상속 받지 못하도록 제한
Virtual
가상 함수나 클래스를 위한 키워드. C++에서는 다형성 사용 시 사용 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <iostream>
using namespace std;
class Parent {
private:
int ID = 0;
public:
Parent() {}
int getID() {
return ID;
}
}
class Child : public Parent {
private:
int ID = 1;
public:
Child() {}
int getID() {
return ID;
}
}
int main(void) {
Parent* p = new Parent();
Parent* c = new Child();
cout << p->getID() << endl;
cout << c->getID() << endl;
}
위의 경우 결과는
0
0
이 나오게 된다. 하지만 Parent 클래스의 getID에 virtual 키워드를 붙이게되면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <iostream>
using namespace std;
class Parent {
private:
int ID = 0;
public:
Parent() {}
virtual int getID() {
return ID;
}
}
class Child : public Parent {
private:
int ID = 1;
public:
Child() {}
int getID() override {
return ID;
}
}
int main(void) {
Parent* p = new Parent();
Parent* c = new Child();
cout << p->getID() << endl;
cout << c->getID() << endl;
}
아래와 같이 결과가 나오게되고, 이때 Child getID 함수에 override를 붙여서 명시적으로 오버라이딩 했다는 것을 나타낼 수 있고 이럴 경우 함수 형식이 부모와 다르다면 컴파일 에러가 난다. (override를 명시하지 않으면 다르더라도 컴파일 에러가 나지 않음)
0
1
Deep / Shallow copy
Shallow copy
얕은 복사. 객체를 복제하긴하지만, 객체 내부의 Mmutable 객체들은 같은 객체를 가짐
Deep copy
깊은 복사. 객체와, 객체 내부의 모든 객체까지 복사하여 새로운 객체를 가짐
하둡
하둡
만약 빅데이터를 처리하려고 할 때, 분산되지 않은 하나의 시스템이 큰 용량의 디스크를 가지고 있고, 여기서 데이터를 검색, 추출 한 다음 사용자에게 제공하려 한다면 데이터 접근 시간에 엄청난 시간이 소모된다. 하지만, 하둡과 같은 대용량 데이터 분산 처리 프레임워크는 데이터를 여러개로 분산해서 저장하고, 이 여러개의 작은 데이터들 사이에서 사용자가 원하는 데이터를 검색하고 추출하기 때문에 훨씬 빠르게 데이터를 가져 올 수 있다.
- 세월이 지나며 디스크의 용량은 계속 커져왔으나, 엑세스 속도는 그에 따라가지 못하기 때문에 위와 같은 방식이 효과적이다.
- 하둡은 HDFS라는 저장소와 MapReduce라는 분석 시스템을 통해 분산 프로그래밍을 수행하는 프레임워크.
- 하둡은 RDBMS 보다 저렴하고, 대용량의 데이터를 처리하는데 더 효과적이다.
특징
- Distributed : 많은 수의 컴퓨터에 자룔르 분산해서 저장 및 처리
- Scalable : 용량이 증대되는 대로 컴퓨터를 추가하면됨
- Fault-tolerant : 하나 이상의 컴퓨터가 고장나느 경우에도 시스템은 정상 동작
- Open source : 자바 오픈소스 프레임워크
- Consistency : 쓰기를 할 때 한개의 서버에서 수행하고, 하둡의 블록은 복제 갯수 만큼 복후 완료 메시지를 보내므로 일관성 보장
- Availability : 여러 노드로 분산 처리하여 Auto failover 지원 (오류 수정)
HDFS
Hadoop Distributed File System은 수십, 수백 테라, 페타 바이트 이상의 대용량 파일을 분산된 서버에 저장 후 빠르게 엑세스 할 수 있게 해주는 파일 시스템이다. 저사양 서버를 이용해서도 스토리지를 구성할 수 있어 장점을 가진다. HDFS는 블록 구조의 파일 시스템을 가지고 있고, 파일을 특정 크기의 블록으로 나누어 분산된 서버에 저장한다. 하둡 2.0에서 블록의 크기는 128Mb이다.
HDFS의 원리
RDBMS의 경우 스키마를 통해 체계적으로 관리되는 것이 비해 하둡은 각 파일 저장소에 블록 단위로 데이터를 나누어 넣기만한다. 기존 분산 처리 시스템의 경우 MPI(Message Passing Interface)를 통해 분산처리시스템끼리 통신을 하는데, 이때 하나의 컴퓨터만 고장나도 시스템이 작동하지 않고 인터페이스가 복잡한 등 문제점이 있었지만, 하둡의 HDFS는 같은 데이터를 3개의 카피를 나누어 분산 처리하기 때문에 좀 더 고장이나 에러에 효과적이다.
HBase
HDFS 위에서 동작하는 Key-Value 구조 분산 데이터 베이스로 구글의 빅테이블을 참고하여 Java로 개발되었다.
- 아키텍쳐 : Master - Slave 구조
- 구성 환경 : 복잡 (HBase, HDFS, ZOOKEEPER 필수 필요)
- 복제 : 복제 HDFS를 이용해서 Block replication
- Sharding : Row key 전체가 Sharding key, Range 방식으로 분산,
- 하둡 자체가 저장소라 분석용 데이터 센터로 연동이 용이하다.
하둡 프레임워크
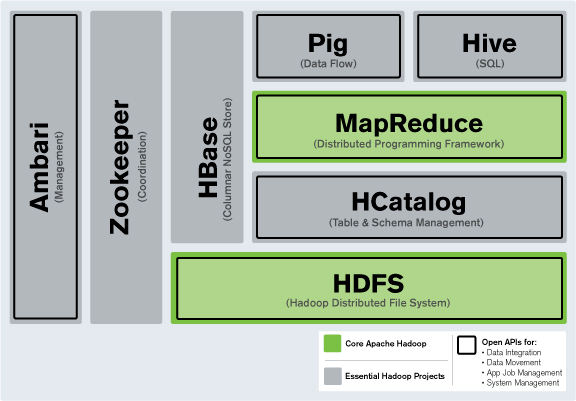
MapReduce
분산 처리를 통해 데이터에 접근할 수 있도록 만들어주는 역할을 한다. Map과 Reduce 단계로 나눠 지는데, Map 단계에서는 데이터를 Key, Value로 묶어주고, Reduce 단계에서는 Map단계의 Key를 이용해 필터링 및 정렬 처리를 한다. 하둡은 MakReduce Job을 이용해 이들을 제어한다.
하둡 에코 시스템
하둡에 더해 여러가지 소프웨어가 추가된 시스템을 하둡 에코 시스템이라 한다. Hbase, Solr, Zookeeper, Hive등이 있다. 여기서 각 소프트웨어들에 필요에 맞게 모듈이 추가되었다고 생각하면된다.
- 하둡 코어 프로젝트 : HDFS, MapReduce
- 서브 프로젝트 : 수집, 분석, 마이닝 등
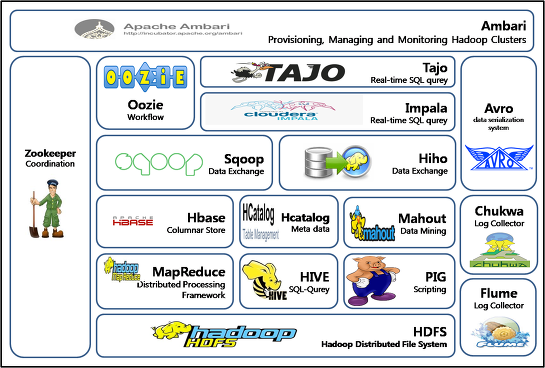
Zookeeper
분산 시스템간의 정보 공유 및 상태 체크, 동기화 등을 처리하는 Coordinate 프레임워크
Oozie
하둡의 워크플로우 관리. 일정한 시간이 경과하거나 주기적으로 반복해서 실행될 수 있는 잡들에 대하여 관리하고, MapReduce Job, Pig Job 등의 시작과 완료 및 실행 중 에러 이벤트 콜백 가능
Avro
다양한 언어의 데이터를 직렬화해줘 쉽게 공유할 수 있도록 해줌. 스키마는 보통 JSON으로 작성
Parquet
데이터 열을 기준으로 데이터를 저장해 효율적으로 저장공간을 절약하고 성능을 향상시켜줌
Flume
웹서버에서 로그 파일을 수집하고 로그 이벤트를 저장소에 전달
Sqoop
RDBMS와 같은 정형적인 데이터 저장소에서 데이터를 추출하도록 도와줌
Pig
하둡의 MapReduce를 단순화시킨 프레임워크
Crunch
MapReduce의 파이프라인을 작성하는 API. Work Flow의 개별 MapReduce Job을 직접 관리할 필요가ㅏ 없어 편함
HBase
분산형 파일 시스템을 사용하는 열기반 DB. RDBMS의 비확장성과 비분상 등의 단점을 커버하고, 노드만 추가하면 선형으로 확장도 가능
Hive
자바를 잘모르는 사용자도 빅데이터 분석 및 처리하를 가능하게 해주는 프레임워크. HiveQL이라는 자체 쿼리 제공. HiveQL의 쿼리는 MapReduce의 Job으로 변환되어 실행
Impala
하이브와 유사한 SQL 질의 시스템. MapReduce를 사용하지 않고 자체 개발 엔진 사용. HiveQL 쿼리를 이용하고 HBase와도 연동
MVC / MVP / MVVP 패턴
MVC
- Model-View-Controller의 약자
- 디자인 패턴 중 하나
Model
어플리케이션의 데이터 및 데이터 처리하는 모델
- View를 조작해서 Model의 데이터를 보여주게함
View
사용자에게 어떻게 보여주고 UI를 제공할 것인지
Controller
사용자 입력을 받고 Model의 데이터를 업데이트 및 불러옴
Model1 방식
View와 Controller가 통합

Model2 방식
Model, View, Controller가 모두 따로
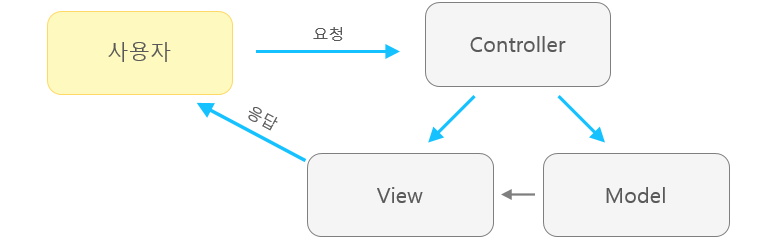
단점
Model과 View가 서로 너무 의존적이라 개발이 복잡해질 수 있음
MVP 패턴
- Model-View-Presenter의 약자
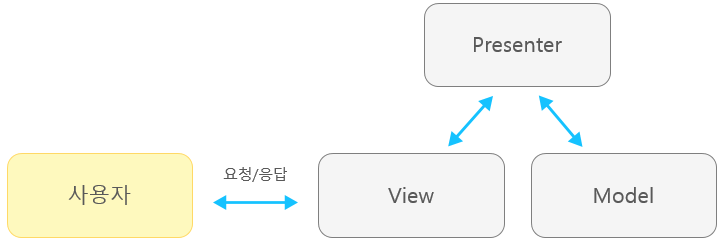
Model/View
MVC와 유사하지만 Model과 View과 직접 연관되지 않음
Presenter
MVC와 다르게 View와 Model을 때어놓음
단점
Presenter와 View가 서로 의존적임
MVVP
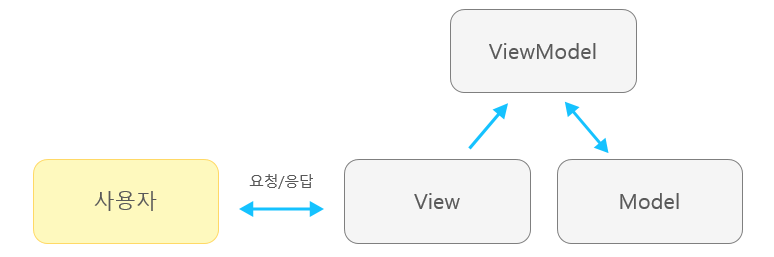
Model/View
MVP와 유사
ViewModel
View를 위한 Model인 ViewModel이 추가됨. 이를 위해 Command 패턴과 DataBining을 이용하는데, 이로 인해 View와 ViewModel관의 의존성을 줄이는 패턴이다.
- View에 입력이 오면 Command 패턴으로 ViewModel에 Command 전달
- ViewModel은 필요한 정보 Model에 요청
- Model은 ViewModel에 데이터 응답
- ViewModel은 응답 받은 데이터 가공해서 저장
- View는 ViewModel과 Data Binding으로 인해 자동으로 갱신
스프링 프레임워크
스프링 프레임워크
- 자바 엔터프라이즈 개발을 편하게 해주는 오픈소스 경량급 애플리케이션 프레임워크
- 자바 엔터프라이즈 : 자바를 이용한 서버 개발을 위한 플랫폼
- 애플리케이션 프레임워크 : 애플리케이션 개발의 전 과정을 빠르고 편리하고 효율적으로 진행하는게 목적인 프레임워크
- 경량급 : 불필요하게 무겁지 않음. 이전 EJB의 경우 프레임워크와 서버환경에 의존적인 부분 때문에 불필요하게 무거웠음
- 자바 엔터프라이즈 개발을 편하게 : 이전 프레임워크와는 근본적인 부분에서 엔터프라이즈 개발의 복잡함 제거함. 사용자는 애플리케이션 개발에 촛점을 맞춰서 개발 가능
- 오픈소스 : 스프링은 오픈소스
- 자바SE의 POJO (Plain Old Java Object)를 자바EE에 의존적이지 않게 연결해줌
- POJO : 평범한 자바 빈즈 (Javabeans) 객체
특징
- 경량 컨테이너로 자바 객체를 직접 관리
- 객체 소멸, 생성 같은 사이클 관리 및 스프링으로부터 필요한 객체를 얻어옴
- POJO 방식 프레임워크
- J2EE 프레임워크 처럼 특정 인터페이스를 구현하거나 상속 받을 필요가 없어 기존 라이브러리 등을 지원하기 용이하고 가벼움
- 자바SE로 된 자바 객체(POJO)를 자바EE에 의존적이지 않게 해줌
- 제어반전 형식 (IoC : Inversion Of Control)
- 컨트롤의 제어권을 스프링이 가지고 있어 스프링이 필요에 따라 사용자 코드를 호출
- 프레임워크와 라이브러리의 차이점이라고 할 수 있음
- 의존성 주입 지원 (DI : Dependency Injection)
- 각 계층, 서비스가 서로 의존성이 존재하면 프레임워크가 연결해줌
- 객체를 필요로 하는 함수에 인자로 넘겨주는 것
- 객체 의존성을 설정 파일에 설정하면 자동으로 의존성 주입을 해줘 사용자가 번거롭지 않게 해줌
- 아래와 같이
B b = new B();는 사용자가 직접 의존성을 주입한 것이지만, 스프링 프레임워크에서는 설정을 해두면 스프링 컨테이너가 만들어놓은 instance(bean)을 가져와 사용하면됨
class A { B b = new B(); public void print() { b.a(); } } class B { public void a() { System.out.println("Print!"); } } - 관점 지향 프로그래밍 (Aspect-Oriented Programming)
- 로킹, 보안, 트랜젝션 등 여러 모듈에서 공통적으로 사용하는 기능을 분리하여 관리 가능
- 객체 지향 보조 역할로 봐도 된다.
- 객체 지향을 하면서도 문제점이 생기게되어 각각의 모듈(클래스) 안에서 조차 중복되는 코드가 발생하였고, 이를 횡단 관심사 (Crosscutting-Concerns)라고 한다. 보통 트랜젝션, 로깅, 성능 분석 등이 있다. 이러한 횡단 관심사들은 전체 모듈에서 모두 등장하게 된다.
- Deep Play님 블로그 참고
- cocomo님 블로그 참고
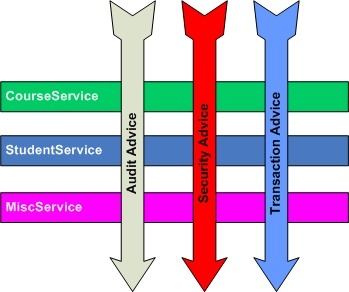
- MVC 패턴 지원
- Controller (Controller)
- Repository (DB)
- Model (Javabeans)
- View (Html)
- 대한민국 전자정부 표준 프레임워크 기반 기술
검색 방식
구글의 검색 방식
1. 크롤링 및 색인(Index) 생성
- 크롤링 : 웹 페이지를 가져와 데이터를 추출함
- 사이트맵 : 사이트 보유자가 제공하는 사이트의 페이지, 동영상, 파일과 각 관계에 대한 정보가 저장됨
- 스파이더 소프트웨어 : 사이트가 주어지면 해당 사이트에 연결된 하이퍼링크를 타고 해당 사이트로 가 다시 탐색을 반복하는 소프트웨어
- 과거의 크롤링 결과 웹 주소 목록과 사이트맵을 사용해서 스파이더 소프트웨어로 웹을 돌아다니며 색인을 생성
2. 검색 알고리즘
- 단어 분석 : 처음 검색어가 주어지면 먼저 검색어의 철자가 잘못된건 없는지 등을 확인
- 최근에는 자연어 데이터까지 사용하여 동의어 중 어떤 의미인지 등 구문을 해석해 사용
- 검색어의 구체성, 광범위성, 범위, 분류 등 고려
- 페이지 분석 : 검색어와 일치하는 정보가 포함된 웹페이지 검색
- 페이지의 제목, 텍스트, 본문 등 어떤 위치에 자주 등장하는지
- 사이트의 문서는 어떤 언어로 작성되었는지
- 걱색어의 환경 또는 배경 고려
- 국가, 위치, 이전 검색 기록 등을 고려하여 맞춤 검색 결과 제공
- 페이지 랭크 : 컨텐츠의 최신성, 등장 빈도, 페이지의 우수성 등을 고려해 스코어를 매김
- 기본적인 구글의 페이지 랭크 알고리즘 PR (Page Rank)
-
P는 페이지, d는 Damping factor로 사용자가 다른 링크를 클릭할 확률이라 보면 되고 0.85정도가 논문의 실험적 최적값, C는 페이지 내의 링크 갯수
- 선형 대수로 나타낼 수도 있음
-
A를 웹들의 인접 행렬 (Adjacency Matrix) 이라고 하고, S는 사이트 내의 링크 갯수로 나눈 행렬, S에서 링크가 없는 페이지는 1/n을 기본값으로 채워줌. E는 전체가 1/n으로 채워진 행렬이고 이 때 구글 랭크를 G라고 두고, G의 고유 벡터 (Eigen Vector) 중 고유값 (Eigen Value) 이 가장 큰 값을 고르면 PR이라고 볼 수 있음
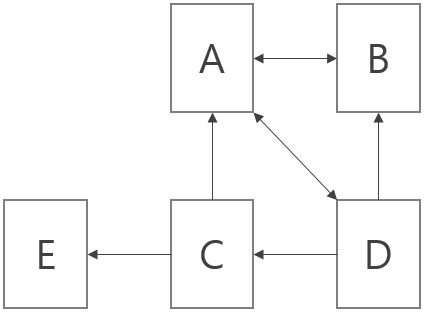
-
- 1에서 만든 색인에서 검색어를 기반으로 사이트들의 리스트를 뽑고 해당 리스트를 페이지 랭크에 따라 정렬해서 보여줌
3. 다양한 검색 결과
- 검색 결과를 단순히 사이트의 리스트로 보여주는 것이 아니라, 날씨일 경우 날씨 정보를 상단에 보여주고, 일기예보의 경우도 마찬가지
- 다양한 검색 결과를 보여줌
JVM (Java Virtual Machine)
- Javac(자바 컴파일러)에 의해 만들어진 Byte code(.class파일)을 OS에 맞게 해석
- OS에 독립적이게 JAVA 실행 가능
- JVM 인스턴스 : 자바 바이트코드로 컴파일된 컴퓨터 프로그램을 실행하는 프로세스
아키텍처
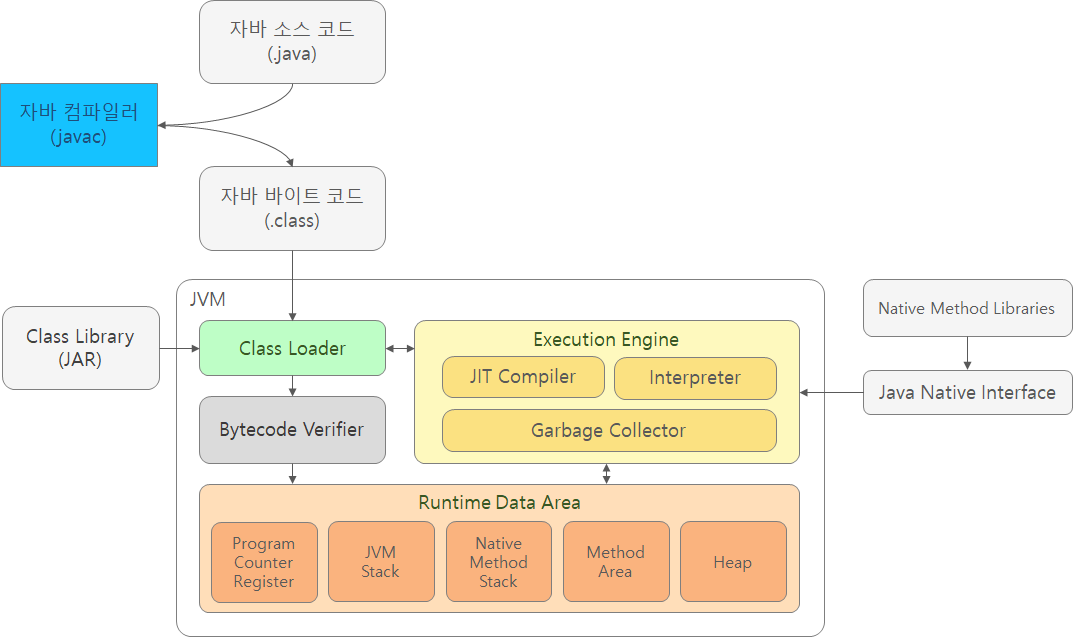
Class Loader
- Loading, Linking, Initialization
- 런타임 중 클래스(
.class)를 로드 (Runtime Data Area에 올려줌) - 바이트 코드가 제대로 작성되었는지 검사
- 객체 생성 시 메모리에 올려줌
- Lazy-loading (지연 로딩), Caching (캐싱) 등을 이용
Bytecode Verifier
JVM으로 로드된 Bytecode가 Execution engine에 의해 Runtime data area에 올라가기 전에 검증을 걸치는 모듈을 말한다. 이를 통해 자바의 보안성을 높이는 역할을 한다.
- 코드가 JVM이 명시한 내용과 같은지 확인한다.
- Memory에 허사 되지 않은 접근이 있는지 확인한다.
- Stack over flow 체크
- Data type 체크
Runtime Data Areas
- 프로그램 수행을 위한 JVM의 메모리 공간
-
PC Register, JVM Stack, Native Method Stack은 스레드마다 생성되며, Method Area, Heap은 모든 스레드가 공유함
Space Description PC Registers 프로그램 카운터 (스레드 용). 실제 PC처럼 레지스터 단에서 작동하지는 않고 Stack 기반으로 작동하고 별도의 메모리 공간에 저장하는데 이 메모리 공간을 PC Register라고 함. Method Byte나 Native Pointer. Native Method 실행 시는 JVM거치지 않고 API로 바로 수행 JVM Stack 스레드를 위한 Stack. 스레드 시작 시 생성되며, 각 스레드 별로 생성. 일반 프로그램에서 Stack 영역이라 생각하면 될 듯 (지역 변수, 임시 변수, 매개 변수 등 저장) Native Method Stack JNI를 통해 호출되는 자바 외 네이티브 코드를 위한 Stack 공간 Method Area 모든 스레드가 공유하는 메모리 영역. 일반 OS의 Data 영역이라고 생각하면됨. Type 데이터들 (클래스, 인터페이스, 메소드, 필드, 전역 변수 등) 보관. 각 Type마다 Runtime Constant Pool을 가짐. 해당 풀은 메소드, 필드, 상수 등의 레퍼런스를 가지고 있어 실제 물리적 메모리 위치 참조. Runtime Constant Pool은 추후 참조해서 실행할 바이트 코드를 따로 찾아 메모리에 적재하는 동적 로딩을 가능하게함 Heap 클래스의 객체를 생성하면 Heap에 저장. 일반 OS의 동적 메모리 할당을 위한 Heap과 같음
Excution Engine
로드된 클래스의 Byte code를 실행하는 런타임 모듈. Runtime Data Area 영역의 바이트 코드를 실행하는 모듈. 자바 바이트 코드 단위로 읽어서 실행
JIT / Interpreter
- 자바 바이트 코드를 기계 언어로 번역해줌
- JVM은 JIT과 Interpreter를 함께 사용함
- 스레드 스케쥴링 담당
- Interpreter : 기존에 JVM은 인터프리터만을 사용했음. 인터프리터는 바이트 코드를 명령어 단위를 읽고 실행하기 때문에 컴파일 방식보다 속도가 느림
- JIT : 인터프리터의 단점을 상쇄하기 위해 도입한 Just-In-Time 컴파일러. JVM은 인터프리터 방식으로 코드를 진행하다가, 해당 코드가 실행되는 빈도수를 체크하여 자주 실행되는 코드를 JIT를 통해 바이트코드를 컴파일하고 이를 캐싱하여 속도를 빠르게 함. JIT로 컴파일된 코드는 인터프리터 형식보다 빠르긴 하지만 컴파일 하는 시간이 오래 걸리기 때문에 융합해서 사용
Garbage Collector
- C/C++등 기존 프로그래밍 언어의 경우 프로그래머가 프로그램 메모리를 관리해줘야 했지만, 자바에서는 JVM이 프로그램 메모리를 관리해줌
- 자바 프로그램에서 사용되지 않는 메모리 지속적으로 찾아내 제거
- 참조되지 않은 객체들 탐색 및 삭제
- GC는 Heap과 Method Area를 관리
Method Area / Heap
-
Heap은 다시 Eden, 두 개의 Survivor, Old 총 4개의 영역으로 나뉘어짐

- Young Generation 영역
- Old 보다 사이즈도 작고 객체가 잔존하는 시간도 짧음
- 대부분 객체는 잠깐 생성되었다가 금방 접근 불가능 상태가되기 때문에 Young에 생성되었다가 사라짐
- 여기서 GC가 발생하면 Minor GC
- Old Generation 영역
- Young 보다 사이즈가 크지만 객체가 잔존하는 시간이 김
- 여기서 GC가 발생하면 Major GC
- Permanent Generation 영역
- Method Area를 뜻함
- 여기서 GC가 발생하면 Major GC
- Old의 객체는 카드 테이블(Card Table)을 가지고 있어 Old의 객체가 Young의 객체를 참조하면 Young 영역에서 GC 발생 시 카드 테이블만 뒤져 Old에서 GC 대상이 무엇인지 판별해 전반적인 GC 시간이 줄어듬
Minor GC
- 최초 객체 생성 시 Eden에 생성
- Eden에서 GC가 발생한 후 남은 객체들을 Survivor1으로 이동
- 1, 2를 계속 반복하면 Survivor1에 객체들이 쌓임
- Survivor1이 가득찼다면 GC 수행 후, 살아남은 객체들을 Survivor2로 모두 옮김 (Survivor1은 빈상태)
- 이후에는 Survivor2에서 2, 3을 실행하고 4에서는 Survivor1으로 모두 옮김 (Survivor2가 빈상태)
- 1 ~ 5를 계속 반복해도 살아 남은 객체 혹은 Eden영역의 살아있는 객체가 Survivor 영역 보다 더 많은 경우 Old영역으로 이동
- 위의 방법을 보면 Survivor1이나 Survivor2 둘 중 하나는 반드시 비어있어야함. 둘 다 데이터가 존재하거나, 둘 다 데이터가 없다면 시스템이 오류를 일으킨것
- HotSpot VM의 경우 더 빠른 메모리 할당을 위해 Bump-the-pointer라는 기술 사용
- Bump-the-pointer : Eden에 삽입된 마지막 객체는 Eden 영역의 가장 위 (Top)에 있는데 이를 가리키는 포인터를 말함. 이 포인터를 이용해 해당 객체가 Eden에 들어갈 수 있는 크기인지만 확인해서 적당하다면 Eden에 삽입. 마지막 객체만 확인하면 되므로 매우 빠르게 객체 할당 일어남
- TLABs(Thread-Local Allocation Buffers) : Bump-the-pointer의 경우 멀티 스레딩 환경이라면 Eden에 객체를 저장할 때 마다 Lock을 걸어야해 비효율적. 이를 위해 TLABs는 각각의 스레드가 Eden에서 일정 부분의 작은 영역을 가질 수 있고 각 스레드는 해당 영역만 접근 할 수 있도록해 Lock없이 메모리 접근 가능
Major GC (Full GC)
- 보통 Old 영역이 가득차면 Major GC를 수행
- 5가지 방법 존재
- Serial GC : Young은 앞의 Minor GC 사용. Old 영역 GC는 Mark-Sweep-Compact 사용. Mark는 첫 단계로 Old에서 살아 있는 객체를 식별. Sweep은 Heap의 앞부분부터 확인하여 살아 있는 객체만 남김. Compact는 각 객체들 사이에 빈 공간이 없도록 메모리를 앞부터 순서대로 정렬. 싱글 코어 CPU에서 사용
- Parallel GC : Serial GC의 병렬화 알고리즘. 기본 알고리즘은 Serial GC와 똑같음. 멀티 코어 CPU에서 사용
- Parallel Compacting(Old) GC : Serial GC와 달리 Mark-Summary-Compact 사용. Sweep의 경우 단일 스레드가 Heap을 훑지만, Summary의 경우 여러 스레드가 Old 영역을 분리하여 훑음
- Concurrent Mark & Sweep GC (CMS)
- Initial Mark : 클래스 로더에서 가장 가까운 객체 중 살아있는 객체 찾음 (짧은 Stop-the-world)
- Concurrent Mark : Initial Mark에서 살아남은 객체의 참조를 따라가며 살아있는 객체를 찾음
- Remark : Concurrent Mark 수행 중 객체가 끈기거나, 새롭게 생긴 객체가 없는지 확인 (짧은 Stop-the-world)
- Concurrent Sweep : 쓰레기 정리
- 별도의 Compaction 단계가 없어 멈추는 시간이 짧지만 시스템 자원을 더 소모하고, Old 영역 크기가 충분치 않거나 크기에 비해 조각난 메모리가 많으면 오히려 Stop-the-world 시간이 늘어남
-
G1(Garbage First) GC
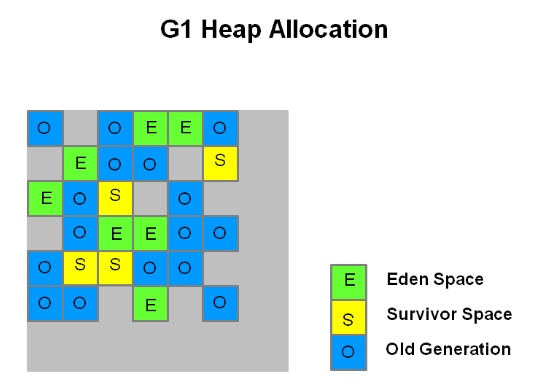
- 앞선 GC들과 달리 Young, Old 나누지 않고 바둑판 모양의 영역이 각각 Eden, Survivor, Old 역할을 모두 함. 역할들이 동적으로 바뀌면서 GC가 일어남
JNI(Java Native Interface)
- 자바로 구현되지 않은 네이티브 코드를 호출 가능하게 해주는 프레임워크
Native Method Libraries
- JNI 실행에 필요한 라이브러리들
RESTful
REST
REpresentational State Transfer 디자인 아키텍처
- WWW 소프트웨어 아키텍처 중 하나
- ROA 따름
SOAP
Simple Object Access Protocol
- SOA 따름
- HTTP, HTTPS, SMTP 등을 통해 XML 기반의 메시지를 커퓨터 네트워크 상에서 교환하는 프로토콜
- 웹 서비스의 모든 데이터가 XML로 표현됨
- 메시지가 SOAP envelope, SOPA header, SOAP body로 구성된 하나의 XML로 표현되어 복잡하고, HTTP상에서 전달되기 무거운 단점이 있다.
SOA
- Service Oriented Arichitecture
- 업무상 일 처리에 해당하는 소프트웨어 기능을 서비스로 보고, 그 서비스가 네트워크 상에 연동하여 시스템 전체를 구축하는 방법
ROA
- Resource Oriented Architecture
- 행동 보다는 리소스에 주안
- HTTP 사용
- URI에 명사 사용
- 리소스의 표현과 분리
아키텍처
- Resource (URI) : 자원
- Services (HTTP : POST, GET, PUT, DELETE) : 액션
- Representation (JSON, XML 등) : 표현
- 목표
- 컴포넌트들간 상호 연동성 : REST는 HTTP와 URI를 사용하는 아키텍쳐로 상호 컴포넌트간 연동이 편하다.
- 범용 인터페이스 : 범용적인 HTTP와 URI를 사용한다.
- 컴포넌트들의 독립적인 배포 : 각기 다른 기능을 가진 컴포넌트를 독립적으로 배포 가능하다.
- 지연 감소, 보안 강화, 레거시 시스템을 인캡슐레이션하는 중간 컴포넌트로 역할 : 클라이언트가 엔드 서버에 직접 접속하지 않고 중간의 REST서버에 접속을 하고 REST서버가 엔드 서버와 연결되어 클라이언트와 엔드 서버 중계 역할을 할 수 있다. 이 경우 로드 밸런싱, 공유 메모리 등을 적용할 수 있고 보안 정책 적용도 쉬워진다.
CRUD
Create, Read, Update, Delete의 약자로 각각 HTTP의 Post, Get, Put, Delete로 맵핑가능하다.
장점
- 서버를 데이터 저장소라 생각해 클라이언트의 이식성 높아짐
- 클라이언트가 UI와 유저 상태 고려
- 서버가 더 간단해짐
- 서버와 클라이언트 따로 개발 가능
- Stateless : 서버는 클라이언트 상태를 저장하지 않음
- Cacheable : 클라이언트가 응답을 캐싱 가능
REST 디자인
- Uniform interface : REST를 디자인한 가장 큰 이유
- 아키텍처를 간소화함
- 자원 식별 (Identification of resources) : 각 자원은 요청(Request = URI)에서 확인(Identify) 가능. 하지만 실제 자원과 표현은 별개!
- 표현을 통해 자원 변경 : 클라이언트가 자원의 표현을 안다면 충분히 자원을 조작 가능
-
자기 서술적 (Self-descriptive message) : 각각의 메시지안에는 자원이 명확하게 명시되어 있음 (읽기 편함). 따로 자원의 원본을 보지 않고도 자원의 정보를 모두 알 수 있어야함.
"students": [ {"name":"Rhino", "major":"Computer Science"}, {"name":"Anderson", "major":"Health"}, {"name":"Peter", "lastName":"Statistics"} ] - HATEOS (Hypermedia As The Engine Of Application State)
- HATEOAS-driven 사이트들은 사이트의 REST 인터페이스에 동적으로 접근할 수 있도록 Response에 링크를 걸어서도 보냄.
- 쉽게 말해 응답 시 추가적인 정보를 위한 링크를 포함할 수 있어야함.
GET /account/12345 HTTP/1.1 HTTP/1.1 200 OK <?xml version="1.0"?> <account> <account_number>12345</account_number> <balance currency="usd">100.00</balance> <link rel="deposit" href="/account/12345/deposit"/> <link rel="withdraw" href="/account/12345/withdraw"/> </account>
- HTTP 기반 RESTful API는 다음으로 정의됨
- URI
- JSON / XML (Media type)
- HTTP 함수 (POST, GET, PUT, DELETE)
- Hypertext Link (State, Resource)
- REST에서 Request/Response 시 최대한 HTTP 표준을 따르는게 좋음
- 처리 결과가 만약 성공이라면, Body에 이를 포함하는게 아닌 HTTP Status에 이를 표현
REST 단점
- point-to-point 통신 모델 기반이라, 서버와 클라이언트가 연결을 맺고 상호작용 (Stateful) 해야하는 프로그램에는 적합하지 않다.
- REST는 디자인 아키텍쳐일뿐 보안, 통신 규약 등을 명시하지 않으므로 이런 내용은 개발자가 맡아서 해야함.
- HTTP에 의존적.
- CRUD의 4가지 메소드만 제공하므로, 기타 모호한 기능 구현을 위해서는 REST 따르기 힘듬.
객체 지향 설계 (Object-Oriented Programming, OOP)
현실 세계의 추상화를 프로그래밍 관점에서 설계를 말한다. 현실 세계의 사물들을 하나하나를 객체라 보고, 그 객체들이 가지는 공통 속성을 상속을 통해 표현하고, 그 속성에서 필요한 부분을 가져와 프로그래밍 한다. 이를 추상화라 한다.
객체 지향 프로그램 설계 원칙
단일 책임 원칙 (SRP, Single Responsibility Principle)
클래스는 단 하나의 책임을 가져야하며 클래스 변경의 이유도 하나여야한다.
개방 폐쇄 원칙 (OCP, Open-Closed Principle)
SW 개체(클래스, 모듈, 함수 등등)는 확장에 대해서는 열려있고, 수정에 대해서는 닫혀 있어야 한다.
리스코프 치환 원칙 (LSP, Liskov Substitution Principle)
상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상 작동해야한다.
인터페이스 분리 원칙 (ISP, Interface Segregation Principle)
인터페이스는 해당 인터페이스를 사용하는 클라이언트를 기준으로 분리해야한다.
의존 역전 원칙 (DIP, Dependency Inversion Principle)
고수준 모듈은 저수준 모듈의 구현이 의존해서는 안된다.
객체 지향 특징
추상화 (Abstraction)
특정 상황에 중요한 속성을 뽑아냄
정보 은닉 (Information Hiding)
불필요하거나 중요한 정보를 숨긴다. 사용자는 이 정보를 모르고도 사용이 가능하게 만든다.
캡슐화 (Encapsulation)
논리적으로 연관된 것들끼리 하나로 묶는 것을 뜻한다. 코드 재활용성을 높이고, 에러발생 최소화.
다형성 (Polymorphism)
하나의 인터페이스가 서로 다른 구현 방법을 가짐.
TDD (Test Driven Developement)
매우 짧은 개발 사이클을 반복해 소프트웨어를 개발하는 프로세스이다. 먼저 개발자는 요구되는 기능에 대한 자동화된 테스트 케이스를 작성하고, 해당 테스트 케이스를 통과하는 코드를 작성한다. 그 후 요구 사항의 변경 등 상황에 맞게 리팩토링을 거치며 테스트 위주의 개발을 진행한다.
Git flow, Github flow, GitLab flow
Git Flow
- 기본 브랜치 5개가 존재
feature > develop > release > hotfix > master - Merge된
feature,release,hotfix브랜치는 삭제한다.
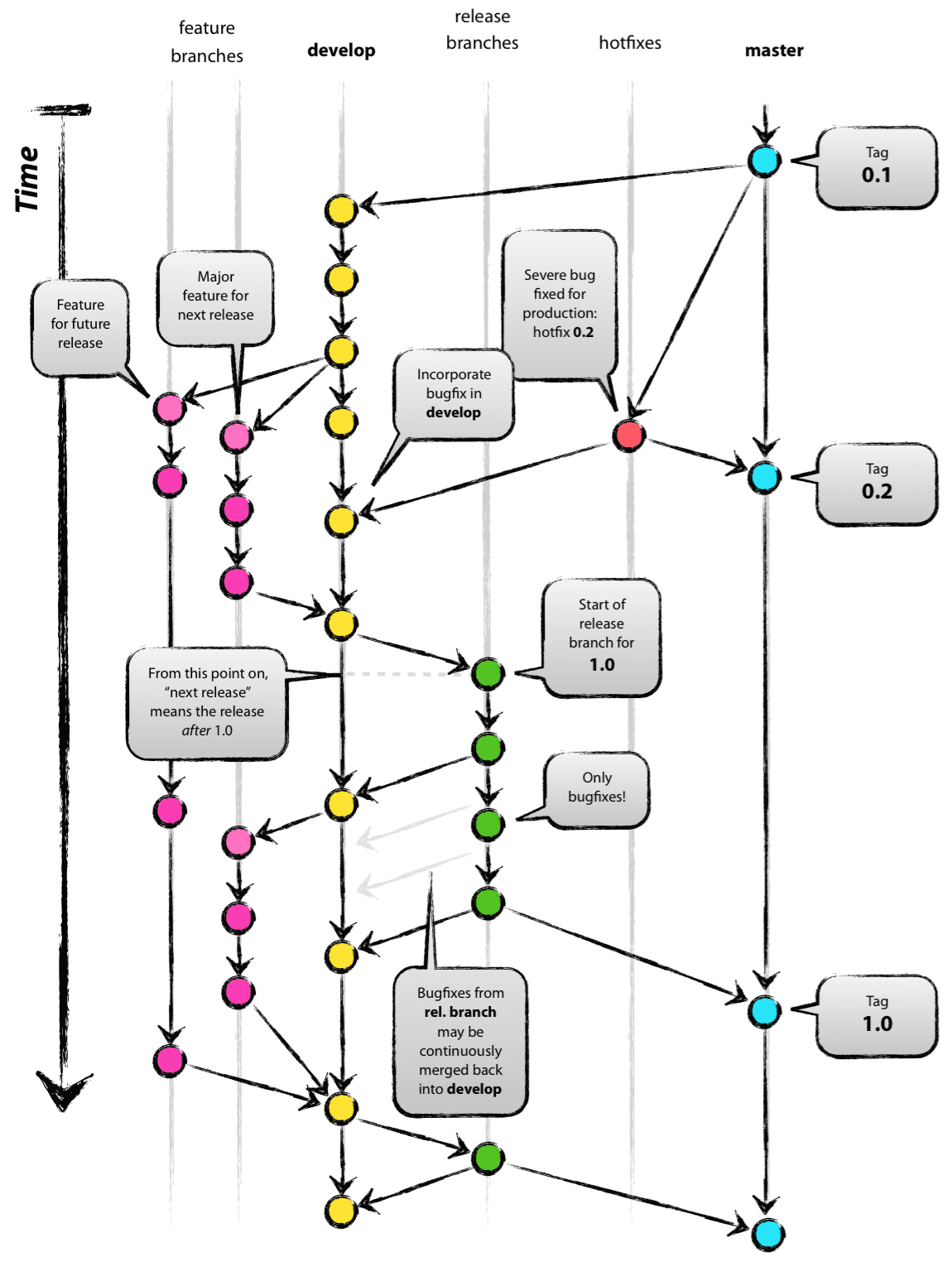
Branches
Feature 브랜치
develop 브랜치에서 나오고 develop 브랜치로 들어간다.
- 새로운 기능을 추가하는 브랜치이다.
- 개발자의 브랜치에만 머물도록 한다.
Release 브랜치
develop 브랜치에서 나와 develop과 master 브랜치로 들어간다.
- 새로운 Production 릴리즈를 위한 브랜치이다.
- 이때까지 완료된 기능을 묶어
develop브랜치에서release브랜치를 따내고,develop에서는 다음 번 릴리즈에 사용할 기능을 추가한다. release브랜치에서는 버그 픽스만을 하고 배포가 준비되면master로 Merge한다. 이때 완료된 기능을develop기능에도 합치기위해develop브랜치에도 Merge 한다.
Hotfix 브랜치
master 브랜치에서 나와 develop과 master 브랜치로 들어간다.
- 실제 배포되는 프로그램에서 발생된 버그는 여기서 수정하고, 수정한 다음 반영을 위해
master와develop브랜치로 반영한다. release브랜치도 있다면,release에도 반영한다.
Github Flow
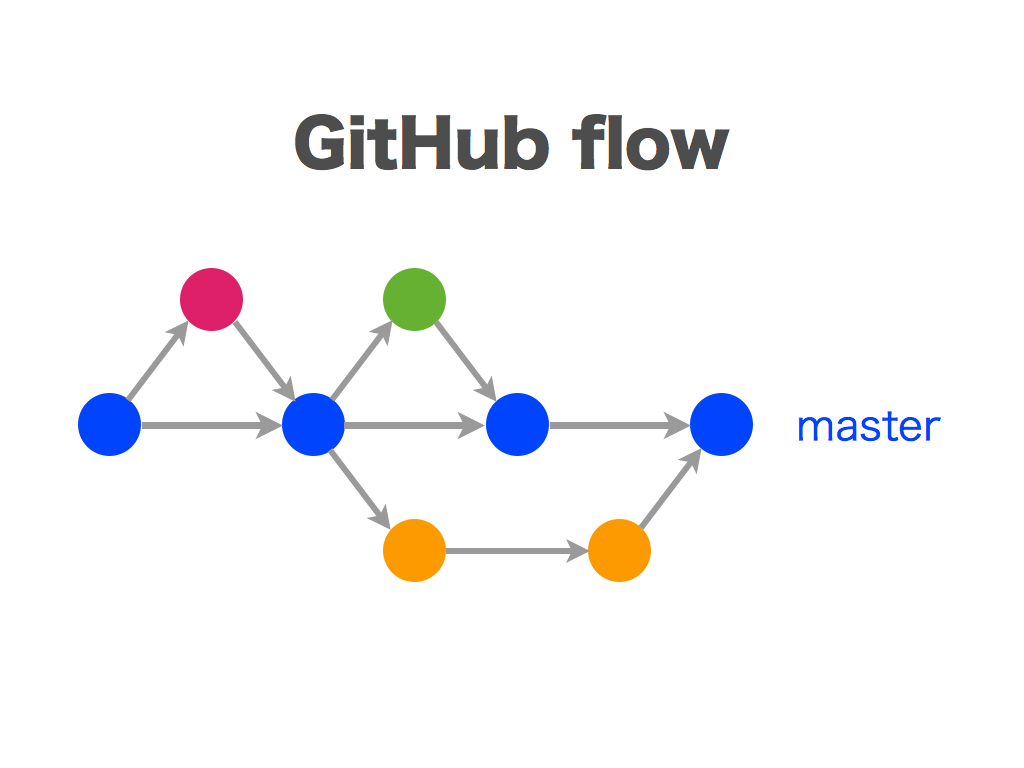
Git Flow보다 상대적으로 간단하다. master 브랜치와 그 이외 브랜치로 구성되고, master 브랜치에 대한 룰만 정확히 지킨다면 나머지 브랜치는 신경쓰지 않는다. pull request로 master에 Merge 시 프로젝트 관리자에게 코드 리뷰 및 검토를 받도록 한다.
master브랜치는 언제든 최신 상태고, 배포 가능한 상태여야한다.- 다른 브랜치를
master에서 딸 때 어떤 일을 하는지 브랜치 이름을 명확히 명시한다. - 원격지 브랜치로 수시로 push하여 다른 사람이 항상 어떤 일을 하는지 알도록 한다.
- 피드백이나 도움 혹은 Merging 준비가 완료 됐을 때
pull request를 생성해 프로젝트 관리자들이 코드 리뷰를 하고 도와주도록 한다. 문제가 없다면master브랜치로 Merge하기도 한다. master로 Merge 후 Push가 되었을 경우 바로 배포되어야 한다.
GitLab Flow
Github Flow가 너무 간단하여, 이를 보완하기 위해 추가적으로 덧붙여 설명한 것을 GitLab FLow라 한다.
- Github Flow와 마찬가지로
pull request를 사용하여 Merge/Pull을 한다. - 긴 시간 작업이 필요한 상황에 대해
issue를 생성하여 작업을 진행한다.
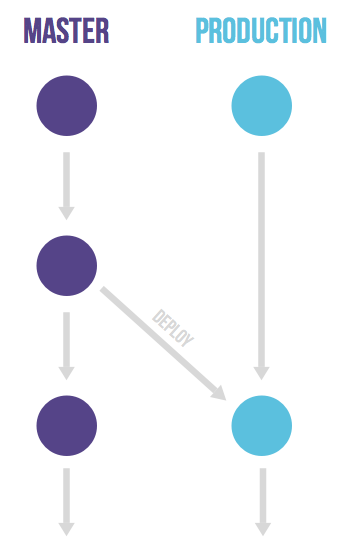
production브랜치가 존재하고, 이 브랜치에는 커밋한 내용들을 일방적으로 Deploy 한다.master와production사이에pre-production브랜치를 두어 개발한 내용을 곧장 반영하지 않고 시간을 두고 반영할 수도 있다.
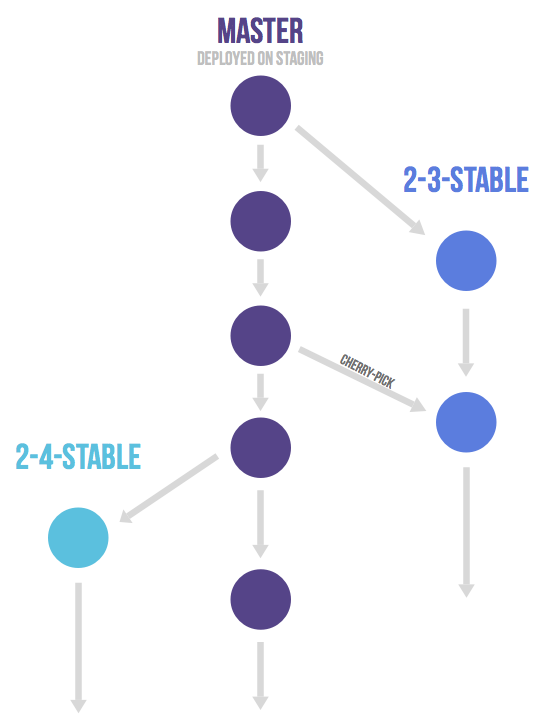
release한 브랜치들 중 보안상 문제나 버그가 발생하였을 경우 Cherry-pick을 이용해서 작업을 진행할 수도 있다.
웹표준 접근성
- 웹 = 문서라고 생각하면됨
- 웹 표준이란, 웹이라는 문서(HTML)을 작성하는 양식을 말함
- HTML 문서 양식을 준수하는 의미론적인 마크업
- 접근성 : 가능한 많은 사용자가 불편 없이 서비스를 이용할 수 있도록 하는 것
- 배경음 사용 금지
- 키보드 사용 보장
- 응답시간 조절
- 정지 기능 제공
- 사용자 요구에 따른 실행
- 오류 정정
아이디어
[실시간] 검색어 보기 쉽게 시각화
- 현재 실시간 혹은 일반 검색어는 단순히 우측에 숫자만 표시하는 등 사용자가 명확히 얼마나 뜨는지 파악이 힘듬
- 한 눈에 보기 쉽고, 비교도 잘되게 나타낸다면 사람들이 더 관심을 가지고 이해하기 쉬울 것
- 연관 검색어도 그래프 형태로 보기 쉽게 나타낸다면 어떨까?
- 네이버의 실시간 급등 검색어 수식
- 기대 횟수는 15초 마다 산출, 관측 횟수는 10분간
이미지 검색
- 현재 다음은 꽃 검색 지원
- 이미지 자체의 피쳐를 뽑아 검색어 쿼리로 집어넣고, 해당 이미지와 유사한 이미지가 나오게 (Vector 거리 등으로) 계산하면 유사한 이미지 찾을 수 있지 않을까?
- 이미지 자체에서 목적으로 하는 영역을 Crop할 수 있게 사용자가 전처리하게
- 사용자가 이미지의 카테고리를 정해서, 특정 카테고리에서 검색 가능하게
카카오톡
- 카카오톡 전체 톡방에 대한 검색