데이터베이스 정리
데이터베이스(DB) 정리
왜 DBMS를 사용하는가?
DBMS
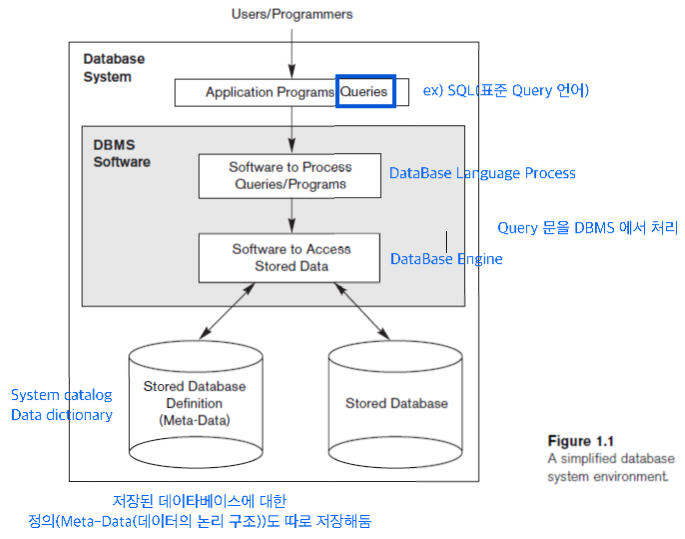
DBMS (Database Management System), 데이터베이스 관리 시스템
- DB를 사용자가 만들고 관리할 수 있게 해주는 프로그램
- DB를 정의 한다는 것은 DB에 들어갈 데이터 타입, 구조, 제약 조건 을 특정하는 것을 말함
- DB에 대한 정의들이나 스펙은 DB Catalog, Dictionary 혹은 Meta-data 라는 이름으로 저장됨
- 쿼리(Query, 질의)란 DBMS에 던지는 질의로서 쿼리를 던지면 DBMS가 그에 맞는 데이터를 보내줌
- 트렌섹션(Transaction)이란 데이터가 DB로 부터 읽어지거나, DB에 쓰여지는 한 번의 과정을 말함
- ACID 속성을 따르는 DB Operation의 배열(Sequence)을 말함
속성 설명 Atomicity (원자성) All or Nothing, 시작에서 끝까지 전체가 성공적으로 수행되었거나, 전혀 수행되지 않거나(부분이 수행되면 안됨) Consistency (일관성) 트렌섹션이 일어나더라도 제약조건을 계속 만족해야함 Isolation (고립성) 여러 트렌섹션이 동시에 일어나더라도 차례대로 실핸한 것과 같은 효과가 나야함 Durability (지속성) 트렌섹션의 데이터는 다른 트렌섹션이 변경하지 않는 한 변경되지 않아야함 - DBMS는 S/W, H/W적인 데이터 방어, 보안을 담당하기도함
- Database System = DBMS + DB
- DDL (Data Definition Language) : Conceptual, External 스키마 정의를 위한 언어
- DML (Data Manipulation Language) : DB 관리를 위한 언어 (Retrieval, Insertion, Deletion, Modification)
- SDL (Storage Definition Language) : Internal 스키마 정의를 위한 언어
- 최근 SDL을 제공하는 언어는 없으며, Internal 스키마는 함수, 파라미터, 스토리지 명세로 이루어짐
DB와 파일 프로세싱의 차이
- 자기기술성(Self-describing nature)을 위해 DB스키마를 저장하는 카탈로그를 이용함
- DB스키마 : DB구조와 제약 조건 등에 관한 전반적인 명세를 기술한 메타데이터 집합
- 프로그램과 데이터가 서로 독립적 (분리해줌)
- 데이터에 대한 여러 사용자 View를 제공함 (필요한 데이터만 볼 수 있도록)
- 데이터 공유와, 다수의 유저의 트렌섹션 프로세싱을 담당
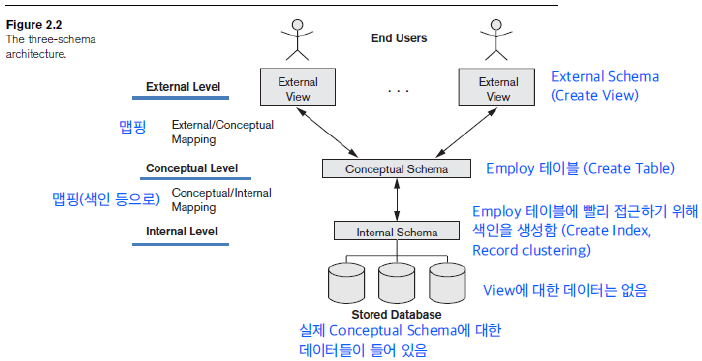
Three-Schema 아키텍쳐
- 사용자 어플리케이션과 물리적 DB를 나누기위해 사용
External 스키마
각각의 사용자에 대한 정보 (=User views), 특정 사용자 그룹에 대해 보여줄 데이터와 숨길 데이터 정의 등
Conceptual 스키마
사용자와 의사소통을 DB의 모든 구조가 정의
Internal 스키마
물리적인 DB 정보, Conceptual 스키마의 실제 정보가 들어있음, 물리적인 스토리지 구조에 대해 정의
- 맵핑(Mapping) : 만약 사용자가 데이터에 접근하려 한다면 Exterenal -> Conceptual -> Internal 까지가서 데이터를 가져온 다음 반대로 Internal -> Conceptual -> External까지 나오게 되는데 이 때 각 레벨에 맞게 포멧을 변경하는 것을 맵핑이라 한다
데이터 독립성 (Data Independence)
한 레벨의 스키마를 수정하더라도 상위 레벨의 스키마에는 변화가 없는 DB의 능력
Logical Data Independence
Conceptual 스키마를 수정하더라도 External 스키마나 어플리케이션 프로그램에 영향을 주지 않음. View 정의 정도는 수정해줘야함
Physical Data Independence
Internal 스키마를 수정하더라도 Conceptual 스키마를 바꿀 필요는 없음, 그렇기 때문에 External 스키마도 수정하지 않아도됨
Relational Data Model (관계 데이터 모델)
Relational Data Model
Table과 집합 이론, 1차 Predicate 로직을 사용한 모델
- Oracle DBMS가 사용
- SQL 쿼리 언어 가 상업적 DBMS의 표준
- Relational algebra와 Relational calculus는 관계 모델의 형식 언어. Relational calculus는 SQL 언어 제작 시, Relational algebra는 DB 구현 및 쿼리 프로세싱과 최적화 시 사용
Operation
- Retrieval : query
- Modification : insert, delete, update
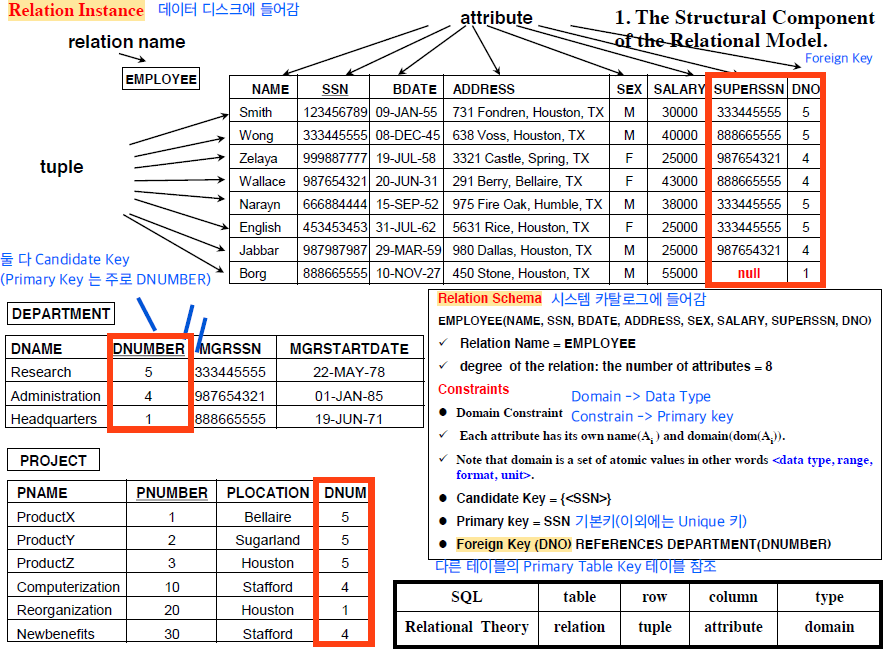
The Structure Component of the Relational Model (구조)
Relation, 관계의 구조 (Tuple, Attribute, Value 등)
Relation 스키마 R(A1, A2, … An)
- R은 Relation 이름, A1 ~ An은 Attribute 들
- Relation 안의 튜플은 순서를 가지지 않음 (집합)
| 스키마 | 설명 |
|---|---|
| Tuple | 값들의 순서 리스트, t=<v1, v2, …, vn>, n-tuple이라고도 함 |
| t[Ai], t.Ai | 튜블 t의 Attribute Ai의 값, dom(Ai)의 한 원소 |
| Domain (dom) | Attribute가 가질 수 있는 값의 집합, 제약 조건이라 할 수 있음 |
| t[Au, Aw, …, Az], t.(Au, Aw, …, Az) | Attribute Au, Aw, .. Az의 값을 포함하는 서브튜플 <vu, vw, … vz> |
| R에서 D로의 맵핑 | D = dom(A1) U dom(A2) U … U dom(An) 일 때 Tuple t를 R에서 D로의 맵핑이라함 |
| Relation Instance | r(R) or r : r(R) = {t1, t2, …, tm}, 튜플의 집합 |
The Integrity Component of the Relational Model (완전성)
Constraints, 제약 조건, Relation의 모든 Relation instance들이 만족해야하는 조건
Key Constraint
- NULL Value : 해당 사항 없음 혹은 누락
| 키 | 설명 |
|---|---|
| Superkey(슈퍼키) | Attribute 집합 A 중 한 Relation 안의 두 튜플 T1, T2의 A 값들이 모두 다를 경우 (T1[A] != T2[A]) A를 Superkey 라함, 유일하지만 최소는 아님 |
| Key(키) | 최소 Superkey라고 생각하면됨. Superkey를 구성하는 Attribute 중 어느 하나라도 빠지면 Superkey가 될 수 없을 경우, 유일하고 최소 |
| Candidate key(후보키) | 키의 집합 |
| Primary key(기본키) | Candidate key 중 선택된 하나의 메인 키, NULL이면 안되고, 동일한 값 중복되어 저장될 수 없음 |
| Alternative key(대체키) | Candidate key 중 Primary key를 제외한 키 |
| Foreign key(외래키) | 릴레이션 R1에서 다른 릴레이션 R2의 Primary key를 가리키는 키, 다른 릴레이션 참조 가능하게 만듬,Foreign key의 도메인은 R2의 Primary key의 도메인과 같아야함, Foreign key의 Attribute들을 Reference라고함 |
Domain Constraint
각 열은 그 열(Attribute)의 <데이터 타입, 범위> 를 만족해야함
- 범위가 데이터 타입 마다 똑같을 필요는 없음
- 범위는 default value (기본값), NOT NULL constraint, CHECK constraint, collations 등등 사용 가능
Constraints on NULLs
NULL, NOT NULL constraints
Entity Integrity Constraints
Primary 키의 열은 무조건 NOT NULL
Referential Integrity Constraints
Foreign 키는 참조하는 Relation의 Primary 키와 같은 것을 가지거나 NULL 값을 가져야 함 (Foreign 키의 허상 참조 방지)
Oracle의 SQL 구문
SQL (Structured Query Language)
변경 연산과 Integry Constraints Violation
변경 연산은 Integrity Constraints를 위반하지 않아야 함
- 위반할 경우 Error 처리 (해당 구문이 수행되지 않은 것과 같음)
- INSERT (삽입) : Integrity Constraints를 위반할 가능성이 있음 (NULL)
- DELETE (삭제) : Referential Integry Constraints를 위반할 가능성 있음 (다른 데이터가 참조하고 있을 수도 있음)
- UPDATA (갱신) : Integrity Constraints를 위반할 가능성이 있음 (이미 참조하는 대상이 있을 경우)
The Manipulative Component of the Relational Model (구현)
Query language, 쿼리 언어 (Relational algebra(Operation 제작) + Relational calculus(SQL 언어 제작))
Relational Argebra (관계 대수)
- Relation들에 대한 질의를 기술하는데 사용하는 기본 연산들의 집합
- 질의 결과 또한 Relation
Unary Relational Operation
- SELECT $\sigma_c(R)$
- Relation R에서 Selection condition c를 만족하는 튜플들을 선택해서 Relation RR을 돌려줌
- c는 R의 Attribute들에 대한 임의의 Boolean expression, RR은 R과 동일한 Attribute 가짐
- c =
[attribute][비교 연산자][상수 값]or[attribute][비교 연산자][attribute] - [비교 연산자] : =, <, >, <=, >=, !=
- AND, OR, NOT으로 c끼리 연결 가능
- c =
- eg
- $\sigma_{DNO=4}(EMP)$
- $\sigma_{SALARY > 30000\ AND\ DNO = 4}(EMP)$
- Oracle SQL :
select * from EMP where (d_id=4 AND salary > 30000) - Selectivity (선택률) : c에 의해 선택된 튜플의 비율
- PROJECT $\Pi_L(R)$
- Relation R에서 L에 명시된 Attribute들만 선택해서 Result relation RR을 돌려줌
- RR이 집합이므로 Duplicate elimination 수행
- eg
- $\Pi_{SEX,SALARY}(EMP)$ : 만약 남자 사원 중 봉급이 10000인 사람이 여러명 있더라도 하나의 튜플만 나온다
- Oracle SQL :
select sex, salary from EMP;
- Sequence of Operations and the RENAME Operation $\rho$
- 몇 개의 연산들이 결합되어 Relational algebra expression을 형성
- eg) 부서 4에 일하는 사원들의 이름과 봉급 $\Pi_{FNAME, LNAME, SALARY}(\sigma_{DNO=4}(EMP))$
- 중간 단계 Relation에 이름 부여 가능
- $DEPT4 \leftarrow \sigma_{DNO=4}(EMP)$
- $R \leftarrow \Pi_{FNAME, LNAME, SALARY}(DEPT4)$
- Result relation에 나타나는 Attribute도 Rename 가능
- $R(FIRSTNAME, LASTNAME, SALARY) \leftarrow \Pi_{FNAME, LNAME, SALARY}(DEPT4)$
- 몇 개의 연산들이 결합되어 Relational algebra expression을 형성
Relational Algebra Operations from Set Theory
- UNION (합집합)
- INTERSECTION (교집합)
- SET DIFFERENCE (MINUS) (차집합)
- CROSS PRODUCT (곱집합)
- UNION, INTERSECTION, MINUS에서는 피연산자 R1, R2의 Attribute 갯수가 같고 서로 Domain이 호환되어야 함
- UNION, INTERSECTION, MINUS의 결과 RR은 R1과 같은 Attribute 이름을 같는다
- eg
- $DEP_EMP \leftarrow \Pi_{DNAME, NAME}(\sigma_{MGRSSN=SSN}(DEPT \times EMP))$
select d.dname, e.name from DEPT d, EMP e where d.mgrssn=e.ssn;
Binary Relational Operations
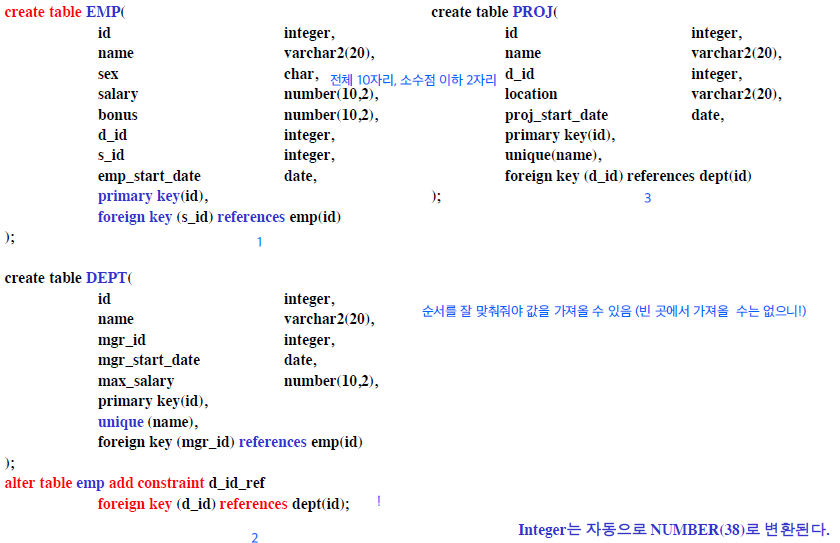
- JOIN $R1 \bowtie_c R2$
- c : Join condition
- 두 개의 Relation R1, R2에서 튜플을 결합하여 긴 튜플을 만들어줌 (R1 기준)
- eg
- 모든 DEPT의 이름과 관리자의 이름 검색
- $RESULT \leftarrow \Pi_{DNAME, FNAME, LNAME}(DEPT \bowtie_{MGRSSN=SSN} EMP)$
select d.dname, e.fanme, e.lname from DEPT d, EMP e where d.mgrssn = e.ssnselect d.dname, e.fanme, e.lname from DEPT d INNER JOIN EMP e ON (d.mgrssn = e.ssn)
- EQUIJOIN : c가 =로 이루어짐
- NATURAL JOIN : 중복 빼고 한 번만 나오게 할 때 사용 (집합)
- Join Selectivity : 조인 결과 튜플 수 / (R1 튜플 * R2 튜플)
- 하나의 Relation도 Join 가능
- $SUPERVISOR(SSSN, SFN, SLN) \leftarrow \Pi_{SSN, FNAME, LNAME}(EMP)$
- $RESULT \leftarrow \Pi_{FNAME, LNAME, SFN, SLN}(EMP \bowtie_{SUPERSSN=SSSN}SUPERVISOR)$
- 관계적으로 완전(Relationally complete) 연산
- Complete set : ${\sigma, \Pi, \cup, \rho, -, \times}$
- DIVISION $\div$
- RDBMS에서 제공 안함
- $S \subseteq R$인 두 Relation r(R), s(R)에 대해
- $r \div s = \Pi_{R-S}(r)-\Pi_{R-S}((\Pi_{R-S}(r) \times s) - r)$
- 쉽게 말하면
R-S Attribute들을 가지는 r'와s의 곱집합을 원래 r이 모두 가지지 않는다면 해당 R-S 튜플을 제외 - eg)
- r(A, B, C, D)={abcd, abef, abde, bcef, edcd, edef}, s(C, D) = {cd, ef}
- $r \div s$ = {ab, ed}
- 왜냐하면 bc의 경우 r에 bccd가 없기 때문
Additional Relational Operations
- Generalized Projection
- Attribute들에 함수 사용할 수 있게
- EMP(SSN, SALARY, DEDUCTION, YEARS_SERVICE)
- $REPORT \leftarrow \rho(SSN, NET_SALARY, BONUS, TAX)(\Pi_{SSN, SALARY-DEDUCTION, 2000 * YEARS_SERVICE, 0.25 * SALARY}(EMP))$
- Aggregate Functions and Grouping
- SUM, COUNT, AVG, MIN, MAX
- 값 혹은 튜플 집합에 사용 가능
- Grouping
- ${<grouping\ attributes>}\Im{<function\ list>}(R)$
- $\Im$ (Script F)
- eg
- 모든 사원의 평균 봉급
- $R(AVGSAL) \leftarrow \Im_{AVG(SALARY)}(EMP)$ (그룹화 안함)
- 각 부서의 부서 번호와 사원 수와 평균 봉급
- $R(DNO, NUMEMPS, AVGSAL) \leftarrow {DNO}\Im{COUNT(SSN), AVG(SALARY)}(EMP)$
- 모든 사원의 평균 봉급
- Oracle SQL
select avg(salary) from EMP;select dno, count(ssn), avg(salary) from EMP group by dnoselect d.dnumber, d.dname, count(ssn), avg(salary) from DEPT d, EMP e where d.dnumber = e.dno group by d.dnumber;
- SUM, COUNT, AVG, MIN, MAX
- Recursive Closure
- 만약 “James Borg” 라는 사람이 지도하는 사람을 알고 싶다면
- $BORG_SSN \leftarrow \Pi_{SSN}(\sigma_{FNAME=’James’\ AND\ LNAME=’Borg’}(EMP))$
- $SUPERVISION(SSN1, SSN2) \leftarrow \Pi_{SSN, SSSN}(EMP)$
- $RESULT1(SSN) \leftarrow \Pi_{SSN1}(SUPERVISION \bowtie_{SSN2=SSN} BORG_SSN))$
- “James Borg” 라는 사람이 지도하는 사람들이 지도하는 사람
- $REULST2(SSN) \leftarrow \Pi_{SSN1}(SUPERVISION \bowtie_{SSN2=SSN} RESULT1)$
- RESULT1, RESULT2를 합하면
- $RESULT \leftarrow RESULT1 \cup RESULT2$
- Oracle SQL
select level, e.name, e.id, e.super_id from EMP e start with id = 10 connect by prior id = e.super_id
- 만약 “James Borg” 라는 사람이 지도하는 사람을 알고 싶다면
- OUTER JOIN
- EQUIJOIN 이나 NATURAL JOIN에서는 R1 또는 R2에 대응되는 튜플이 없으면 결과에 나타나지 않음
- OUTER JOIN의 경우 원하는 Relation의 튜플이 모두 나타남
- INNER JOIN : $R1 \bowtie_c R2$
- LEFT OUTER JOIN : R1의 튜플이 모두 나타남
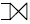
- RIGHT OUTER JOIN : R2의 튜플이 모두 나타남
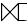
- FULL OUTER JOIN : R1, R2의 모든 튜플이 나타남
- Oracle SQL
- Left :
select e.name, d.dname from EMP e LEFT OUTER JOIN DEPT d ON (e.dno = d.dnumber) - Right :
select e.name, d.dname from EMP e, DEPT d where e.dno = d.dnumber(+)
- Left :
- OUTER UNION
- Attribute들이 모두 있는 FULL OUTER JOIN과 동일한 연산
- Oracle에서는 FULL OUTER JOIN이 없으므로 LEFT OUTER JOIN 결과와 RIGHT OUTER JOIN 결과를 UNION 한다
Relational Calculus
- First order logic (Predicate logic, First-order predicate calculus)에 기반을 둔 형식 언어
- Relational Algebra와 차이점
- Relational Algebra : Procedure language (절차적, 어떻게(HOW) 검색할 것인가)
- Relational Calculus : 선언적 (비절차적, 무엇(WHAT)을 검색할 것인가)
- 두 언어의 Expressive power는 동등
- Relational Calculus는 SQL의 기반
- Relational Completeness (관계적 완전성)
- Relational Algebra와 Relational Calculus의 표현력이 같으므로 관계적으로 완전 (서로가 서로 할 수 있는 일을 할 수 있음)
Tuple Relational Calculus
- 쿼리 :
{ t1.Ai, t2.Ak, ... tn.Am | CONDITION(t1, t2, ..., tn+m) } - CONDITION이 모두 TRUE인 튜플들이 결과가 됨
- eg
{ t | EMP(t) AND t.SALARY > 50000 }{ t.FNAME, t.LNAME | EMP(t) AND t.SALARY > 50000 }
- Atom 단위로 나뉨
- R(ti) : Relation R의 튜플 ti, R에 ti가 있다면 True
- ti.A op tj.B : op는 비교 연산자, A는 ti의 range 안, B는 tj의 range 안
- ti.A op c or c op tj.B : c는 상수값
- Formula (Boolean condition)
- 여러개의 Atom이 AND, OR, NOT으로 연결되어 구성됨
- Existential (어떤, $\exists$) and Universal (모든, $\forall$) Quantifiers
- Bound Tuple Variable : 튜플 변수에 수량사(Quantifiers)가 붙었을 경우
- Free : 튜플 변수에 수량사가 없을 경우
- RULE
- 모든 Atom은 Formula
- F1과 F2가 Formula 라면 (F1 AND F2), (F1 OR F2), NOT(F1) 모두 Formula
- F가 Formula라면 $(\exists t)(F)$도 Formula. 하나라도 튜플이 TRUE라면 $(\exists t)(F)$는 TRUE, 아니면 FALSE
- F가 Formula라면 $(\forall t)(F)$도 Formula. 모든 튜플이 TRUE라면 $(\forall t)(F)$는 TRUE, 아니면 FALSE
- eg
{ t.FNAME, t.LNAME, t.ADDRESS | EMP(t) AND (∃d)(DEPT(d) AND d.DNAME='Research' AND d.DNUMBER=t.DNO)}select e.fname, e.lname, e.address from EMP e, DEPT d where d.dname = 'Research' and d.dnumber = e.dno;- $\Pi_{FNAME, LNAME, ADDRESS}(EMP \bowtie_{DNO = DNUMBER} (\sigma_{DNAME = ‘Research’}(DEPT)))$
- Transforming the Univarsal and Existential Quantifiers
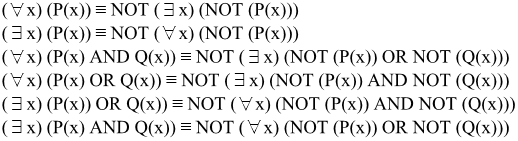
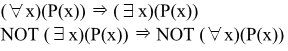
- Safe Expressions
- 결과가 유한개 나올 수 있는 표현을 Safe하다고 함
-
{ t NOT (EMP(t)) } 는 Unsafe (Infinitely numerous)
Domain Relational Calculus
- 튜플 변수 (Tuple Variables) 대신 Domain variables 사용
- Domain variables는 한 Attribute의 Domain을 범위로 가짐
- eg
- 이름이 ‘John B. Smith’인 사원의 생일과 주소 검색 (EMP가 10개의 Attributes 가졌을 경우)
{ uv | (∃q)(∃r)(∃s)(EMP(qrstuvwxyz) AND q = 'John' AND r = 'B' AND s = 'Smith')} - QBE의 경우
{ uv | EMP('John', 'B', 'Smith', t, u, v, w, x, y, z)} - qrstuvwxyz는 EMP의 Attribute에 각각 맵핑됨
- 이름이 ‘John B. Smith’인 사원의 생일과 주소 검색 (EMP가 10개의 Attributes 가졌을 경우)
Database Design Theory
Functional Dependecy
- R이 Relation scheme이라 하고 $V \subseteq R$이고 $W \subseteq R$ 일 경우
- FD (Functional Dependency) $V \rightarrow W$가 R에 대해 만족함
- r(R)의 모든 튜플쌍 t1, t2에 대해서 t1[V] = t2[V] 이면 t1[W] = t2[W] 임
- eg
- $student_id \rightarrow student_name$ (학생 ID가 같으면 학생 이름도 같다)
- $studet_id, course_number, year) \rightarrow grade$ (학생 ID, 코스 번호, 년도가 같다면 점수도 같다)
- $FD\ X \rightarrow Y$에서 X를 Y의 Determinant(결정자)라 함
- $Y \subseteq X$ 일 경우 $FD\ X \rightarrow Y$을 Trivial 이라함
- $X \rightarrow Y$이고 $Z \rightarrow Y$, $Z \subset X$인 Z가 있을 때 Y가 X에 Partially dependent (부분 의존)하다 하고, Z가 없을 경우 Fully dependent (완전 의존)
- eg) $AB \rightarrow C$이고 $A \rightarrow C$라면 C는 AB에 부분 의존
- $X \rightarrow Y$이고 $Y \rightarrow Z$일 경우 Z는 X에 Transitively dependent하다고 한다
- K가 R의 Super 키라면 $K \rightarrow R$
- FD의 집합인 F가 있을 때 다른 FD들이 만족하는지 증명할 수 있을 때 그 FD들을 F에 Logically implied 되었다고 함
Armstring’s Axioms
- $FD\ X \rightarrow Y$에서 좌변 X는 절대 분해하면 안됨
| Rule | Discription |
|---|---|
| Reflexive rule | $Y \subset X$라면 $X \rightarrow Y$ |
| Augmentation rule | $X \rightarrow Y$라면 $XW \rightarrow YW$ |
| Transitivity rule | $X \rightarrow Y$이고 $Y \rightarrow Z$라면 $X \rightarrow Z$ |
| Union rule | $X \rightarrow Y$이고 $X \rightarrow Z$이면 $X \rightarrow YZ$ |
| Decomposition rule | $X \rightarrow YZ$이면 $X \rightarrow Y$, $X \rightarrow Z$ |
| Pseudotransitivity | $X \rightarrow Y$이고 $YW \rightarrow Z$라면 $XW \rightarrow Z$ |
Closure
X가 Attribute들의 집합일 때, X의 Closure($X^+$)는 FD들의 집합 F에서 X에 의해 Functionally determined ($X \rightarrow F$)된 모든 Attribute들의 집합을 말함
1
2
3
4
5
6
7
def compute_closure(X, F) {
result = X;
while(result가 변했으면)
for each FD Y -> Z in F {
if (Y ⊆ result) result = result ∪ Z;
}
}
- R = { A, B, C, G, H, I }
- F = { A → B, A → C, CG → H, CG → I, B → H }
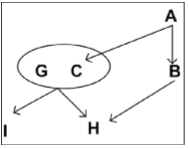
- A → H는 만족하는가? A → B, B → H 이므로 Transitivity 규칙에 의해 만족
- AG → I는 만족하는가? Closure안에 있으면 가능
- $AG^+$ result = AG 1st loop: result = ABG (A → B) result = ABCG (A → C) result = ABCGH (CG → H) result = ABCGHI (CG → I) 2nd loop: 새로운 추가 없음 → 끝 그러므로 AG → I 만족함
- $F^+$ : FD의 집합 F의 Closure는 F로부터 추론할 수 있는 모든 가능한 FD들의 집합이다
Canonical Cover (Minimal Cover)
F의 Canonical Cover Fc는, F가 Fc의 모든 Dependecy들을 Logically implied할 수 있고, Fc 또한 F의 모든 Dependecy들을 Logically implied할 수 있을 때, Dependency의 집합을 Fc라함
- FD에서 어떤 F를 삭제해도 FD의 Closure가 같을 때 F를 Extraneous attribute라 한다
- 모든 $FD\ \ X \rightarrow Y$에 대해 Fc가 X의 Extraneous attribute들을 가지지 않아야함
- 모든 $FD\ \ X \rightarrow Y$에 대해 Fc가 Y의 Extraneous attribute들을 가지지 않아야함
- FD의 좌변은 Fc에서 Unique
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def compute_canonical_cover(F) {
Fc = F;
for each FD X -> Y in Fc {
우변에 Attribute 하나만 남게 분해;
}
똑같은 FD 끼리 Merge;
for each FD X -> Y in Fc {
X_+ = compute_closure(X, Fc - {X -> Y});
if (Y ⊆ X_+) {
Fc = Fc - {X -> Y};
}
}
좌변이 같은 것 Merge;
}
Normal Forms (정규식)
한 릴레이션에 여러 엔티티의 Attribute들이 혼합되게 되면 정보가 중복 저장되어 저장 공간이 낭비된다. 그리고, 이런 중복 저장은 만약 하나의 정보가 갱신되었을 때 어느 정보가 정확한 것인지 알 수 없기 때문에 이런 문제를 해결하기 위해 정규화를 한다.
갱신 이상 (Update Anomalies)
- 삽입 이상 (Insertion Anomalies) : 원하지 않는 자료가 삽입되거나, 삽입하는데 자료가 부족해 삽입이 되지 않는 등의 문제
- 삭제 이상 (Deletion Anomalies) : 하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제
- 수정 이상 (Modification Anomalies) : 정확하지 않거나, 일부의 튜플만 수정되어 정보가 모호해지거나 일관성이 없어져 정확한 정보가 파악이 되지 않는 문제
1NF, 2NF, 3NF, 4NF
- Relation scheme R
- Prime attribute : Attribute가 R의 Candidate 키의 멤버일 경우, 아니면 Nonprime
- Transitivity dependency : $X \rightarrow Y$에서 $X \rightarrow Z$, $Z \rightarrow Y$를 만족하는 R의 호부키도, 어떤 키의 부분 집합도 아닌 Z가 있을 때
- 1NF : R의 모든 Attribute들의 Domain이 Atomic할 경우
- Domain의 요소(Element)들이 분해할 수 없어 보일 때 Domain을 Atomic이라 함
- 2NF : R이 1NF이면서, Nonprime attribute들이 R의 모든 키에 Fully dependent할 경우
- 3NF : R의 Nonprime attribute들이 R의 모든 키에 대해서 Fully dependent하고, Nontransitively dependent할 경우
- BCNF (Boyee-Codd normal form) : R이 3NF이면서, R에서 $X \rightarrow A$이고 $A \not\in X$이면 X가 R의 Super키일 경우
- 3NF, BCNF는 Insertion, Deletion anomaly와 redundancy로 부터 안전하다
First Normal Form (1NF)
- 1NF X
| Student | |
|---|---|
| NAME | SEX |
| {peter, john, david} | male |
| {anna, marry} | female |
- 1NF O
| Student | |
|---|---|
| NAME | SEX |
| peter | male |
| john | male |
| david | male |
| anna | female |
| marry | female |
Transitive Dependency
STUDENT(s_id, s_name, year, dept_id, dept_name)F = { s_id → s_name | year | dept_id | dept_name, dept_id → dept_name, dept_name → dept_name}Fc = { s_id → s_name | year | dept_id, dept_id → dept_name, dept_name → dept_name}Key = s_id- s_id와 s_name, year, dept_id 는 Fully dependent하고, dept_name은 Transitively dependent함
- 문제점
- Redundancy (중복) : 같은 d_id에도 d_name이 또 붙음
- Update Anomaly (변경 이상) : Insertion, Deletion, Modification 시 문제
- d_name을 바꾼다고 한다면 d_id가 같은 모든 튜플을 다시 찾아내서 바꿔야함
- 3NF(BCNF)로 변환 (Nontransitively dependent하게)
STUDENT(s_id, s_name, year, dept_id)DEPARTMENT(dept_id, dept_name)

Partial Dependency
STUDENT(id, name, addr, course, year, grade)F = { id → name | addr, (id, course, year) → grade}Fc = { id → name | addr, (id, course, year) → grade}key = (id, course, year)- 키에 대해서 grade는 Fully dependent하고, name, addr는 Partially dependent함
- 문제점
- Redundancy (중복) : 매 과목마다 학생의 이름과 주소를 새로 기록해야함
- Update anomaly
- Insertion 시 : 과목이 없으면 학생 정보를 기록할 수 없음
- (id, course, year)가 기본키인데 course, year가 NULL이 되버림
- Entity Integrity Constraints가 위배됨
- Insertion 시 : 과목이 없으면 학생 정보를 기록할 수 없음
- 2NF (Nonprime attribute들이 키에 대해 Fully dependent하게 만들어줌)
STUDENT(id, name, addr)GRADE(id, course, year, grade)
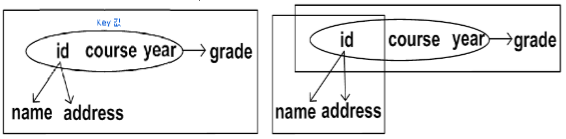
Decomposition
- Lossless-join decomposition : R1, R2가 R이 분해된 것이고, $F^+$안에 $R1 \cap R2 \rightarrow R1$이나 $R1 \cap R2 \rightarrow R2$가 하나라도 포함된다면
- 다르게 말하면
R = R1 JOIN R2라면 분해 가능 - 다르게 말하면 $R1 \cap R2$가 R1이나 R2의 키라면 분해가능
- 다르게 말하면
- Dependecy-preserving decomposition : R1, R2, …, Rn이 R이 분해된 것일 때, $F’=F1 \cup F2 \cup … \cup Fn$이고 $F’^+=F^+$ 일 경우

1
2
3
4
5
6
7
8
9
10
11
12
13
14
def BCNF with Lossless-join decomposition(R) {
result = {R};
done = FALSE;
F_+ 계산;
while(!done) {
for each Ri in result {
if (Ri가 BCNF가 아닐 경우) {
X → Y가 Nontrivial(Y ⊆ X)이고 X → Ri가 F_+ 안에 없고, X ∩ Y = {∅}인 X, Y;
result = result - Ri;
result = result ∪ (Ri - Y);
result = result ∪ (X, Y);
}
}
}
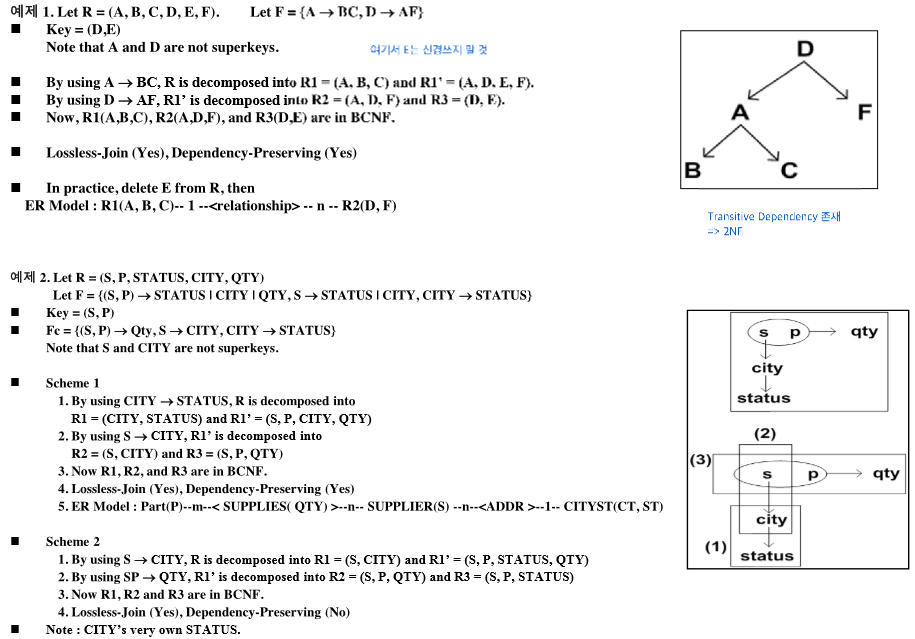
3NF vs. BCNF
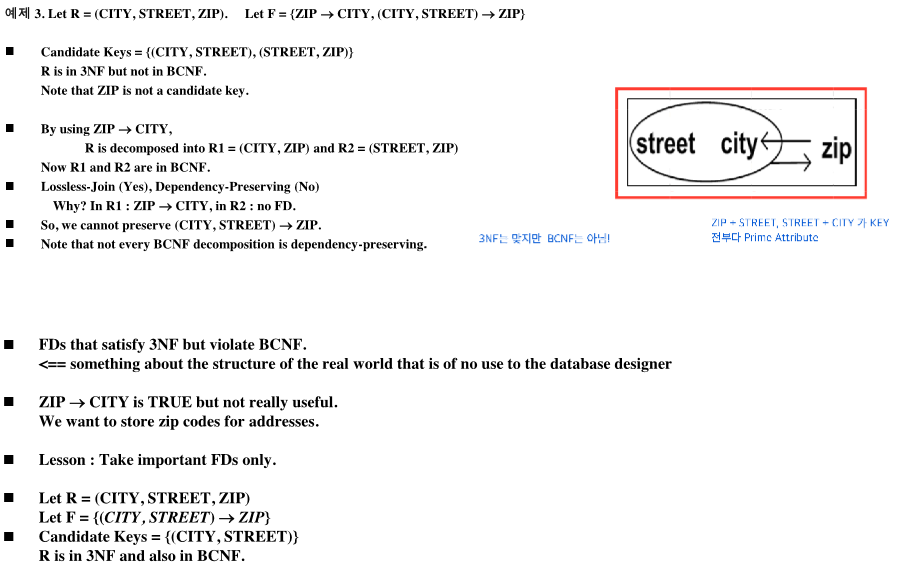
Goal with Funcional Dependencies
BCNF나 안되면 3NF로 만들어야 좋음 (3NF는 무조건 만들 수 있음)
- (1NF(2NF(3NF(BCNF))))
Good Designs
DBMS (Database Management System)
Conceptual Data Modeling Using ER Model
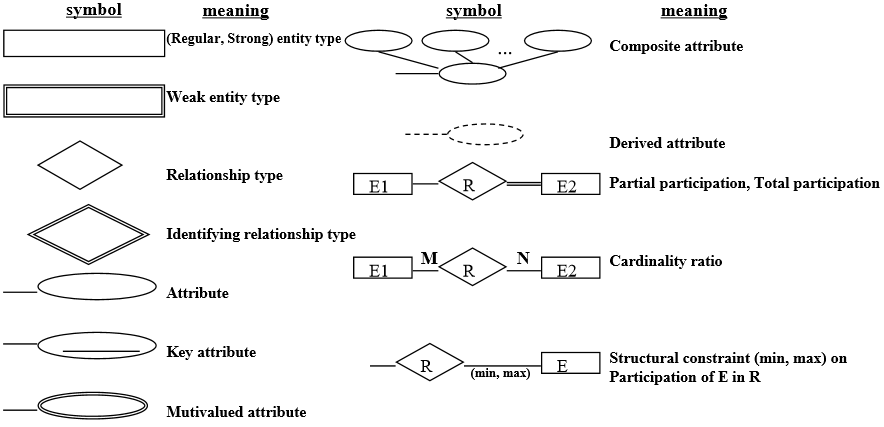
ER(Entity-Relationship)
ER diagram
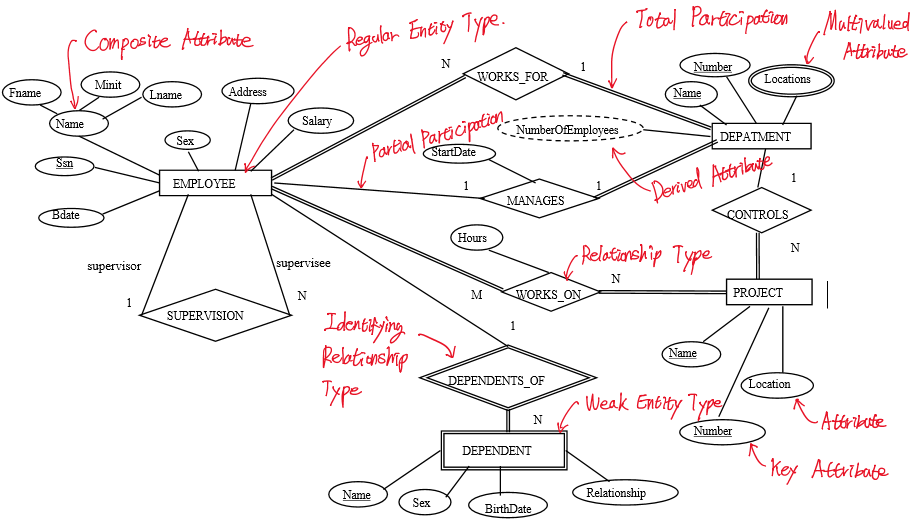
Mapping Company ER schema into a Relational Database Schema
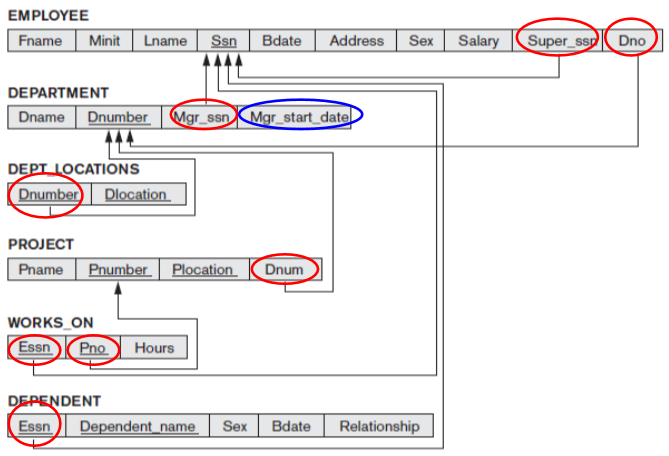
SQL


Example Tables
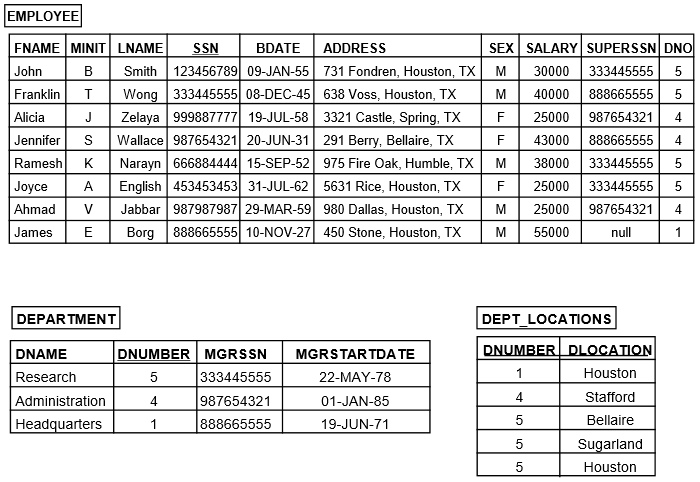
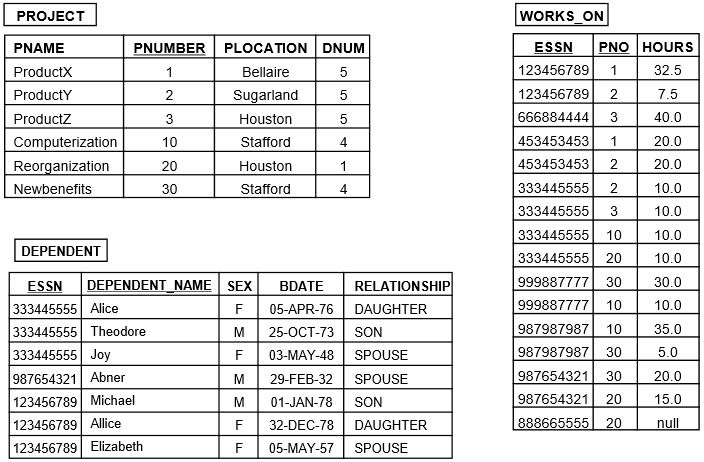
ER-to-Relational Mapping Algorithm
아래 순서대로 진행하면됨
- Regular Entity Types E
- 먼저 E의 Relation R을 만든 후 E의 모든 Simple attribute들을 포함시킨다
- Composite attribute의 Simple component들만 추가 시킨다
- E의 키 중 하나를 Primary 키로 설정한다. 선택된 키가 Composite라면 모두 같이 Primary 키가 된다
- 만약 키가 여러 개라면 Secondary(Unique) 키로 설정해 놓는다 (나중에 Indexing등에 사용)
- Weak Entity Types W
- Owner Entity Type O
- W의 모든 Simple attribute들을 포함하는 Relation Rw를 만든다
- Rw에 O의 Primary 키에 대한 Foreign 키를 추가한다 (W의 Indentifying Relation Type 맵핑)
- W의 Primary 키는 O의 Primary 키와 W의 Key를 조합해서 만든다
- 만약 O 또한 Weak entity type이라면 O먼저 처리한다
- Binary 1:1 Relationship Types R
- 각 Relation Type R에 대해, R에 연관된 S와 T 부터 찾는다
- 3 방법이 가능 Foreign 키, Merged relationship, Cross-reference 방법. 보통 Foreign 키 접근 사용 1. Foreign 키 방법 : 하나의 Relation S를 선택하고, T의 Primary 키를 S의 Foreign키로 넣는다. S는 R에 Total participation하는 Entity로 보면 된다(MANAGES의 경우 S는 DEPARTMENT). R의 모든 Simple attribute들을 S의 Attribute로 넣는다 2. Merged Relation 방법 : S, T 둘 다 Total participation이라면 두 Relation을 묶어버림 (항상 튜플의 갯수가 같다는 말이기 때문) 3. Cross-reference (relationship relation) 방법 : Relation R’을 새로 만들어서 S와 T의 Primary 키를 서로 Referencing하게 한다(M:N Relationship일 경우). 이때 R’를 Rlationship relation이라 한다. R’는 S와 T의 Primary 키를 Foreign 키로 가지고 있고, R’의 Primary 키는 둘 중 하나의 키로 설정하고 다른 하나는 Unique 키로 놔둔다
- Binary 1:N Relationship Types R
- N인 쪽을 S, 1인 쪽을 T라고 하였을 때, S에 Foreign 키로 T의 Primary 키를 넣는다 (WORKS_FOR의 경우 S는 EMPLOYEE, T는 DEPARTMENT)
- Binary M:N Relationship Types R
- R 마다 R을 위한 새로운 Relation S를 만든다. 참여하는 릴레이션들의 Primary 키를 S에 Foreign 키로 넣고 이 키들의 조합을 S의 Primary 키로 둔다. 그리고 R의 Simple attribute들을 S의 Attribute로 넣는다
- Multivalued Attributes A
- A마다 새로운 Relation R을 만든다. R은 A에 해당하는 Attribute를 가지고, 부모의 Primary 키 K를 R의 Foreign 키로 가진다. A와 K를 조합해 R의 Primary Key로 사용한다. A가 Composite이라면 Simple component들을 추가한다
- N-ary Relationship Types R
- N > 2인 R에 대해서 (이때 N을 Relationship의 Degree라 함) 새로운 Relation S를 만든다. S에 연결된 Entity들의 Primary 키를 R의 Foreign 키로 가진다. 그 후 R의 Simple attribute들을 S에 추가한다. S의 Primary 키는 보통 S의 모든 Foreign 키의 집합으로 구성한다. 만약 R에 연결된 Entity E가 1로 연결되어 있으면 Primary 키에서 해당 키를 제외한다
Relationship Types of Degree Higher than Two
Relationship Type에서 Degree가 2 보다 클 경우, 작은 단위로 나눠야 할 수도 있다. 이럴 경우 Degree를 낮추거나, Weak Entity Type으로 쪼개서 해결해야 할 수도 있다
Conceptual Data Modeling Using UML
UML(Unified Modeling Language)은 OMG(Object Management Group)의 표준이다
- 다이어그램을 이용하여 Language의 Syntax나 Life cycle을 알 수 있게 해줌
- 많은 OOP(Object-Oriented Programming) 방법론들을 결합해서 만듬
- 예시로 Class Diagram이 있음
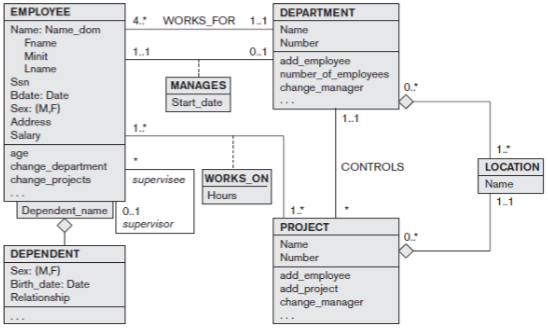
Class diagram
- 박스 가장 위에 클래스 이름 명시
- 인터페이스 이름 위에
<<interface>>명시 - 가상 클래스는 클래스 이름을 이탈릭체로 명시
- Attributes : 클래스의 모든 필드 포함
- Methods : 간단한 것 (get, set)은 제외 할 수도 있음 (인터페이스는 제외하지 말 것), 상속 받은 함수 포함시키지 말 것
- Generalization
- Inheritance between classes : A가 부모, B가 자식
- Interface implementation : A가 인터페이스, B가 구현
- Inheritance between classes : A가 부모, B가 자식
- Association
- Association : 개념상 서로 연결, 한 클래스가 다른 클래스에서 제공하는 기능 사용할 때 표시
- Aggretgation : Class A가 class B 객체를 포인터로 포함 (A가 사라져도 B 안사라짐)
- Composition : Class A가 class B 객체 자체를 가짐 (A가 사라지면 B도 사라짐)
- Dependency : Association과 유사하지만, 한 클래스가 다른 클래스의 메소드를 잠시 사용하는 등 짧은 시간 동안 관계 유지
- Association : 개념상 서로 연결, 한 클래스가 다른 클래스에서 제공하는 기능 사용할 때 표시
- Multiplicity : min…max
- ER에서는 위의 표와 같이 사용함






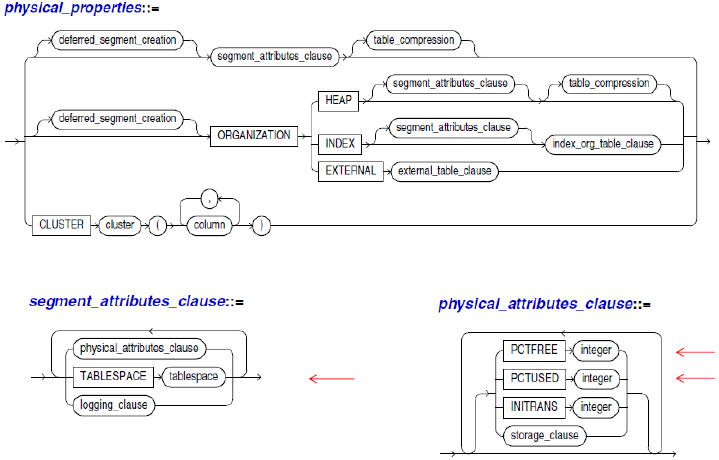
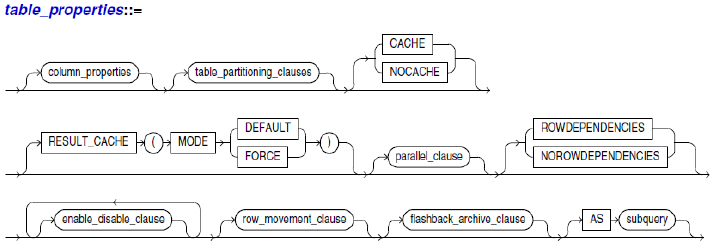
Physical DB Design
Tables in Oracle
-
Relational Tables 가장 일반적인 테이블 타입
CREATE TABLE - Object Tables
테이블 객체를 만듬
CREATE TYPE department_typ AS OBJECT ( d_name VARCHAR2(100), d_address VARCHAR2(200) ); CREATE TABLE department_obj_t OF department_typ; INSERT INTO department_obj_t VALUES('hr', '10 Main St, Sometown, CA'); - 아래 성격을 가진 테이블을 만들 수 있음
- Heap-organized table : 각 튜플이 순서를 가지지 않고 디스크에 저장. CREATE TABLE 명령을 실행하면 Default로 heap-organized table로 만듬
- Index-organized table : B+ - tree index 우선 순위를 가지고 저장소에 저장, Primary 키 순서로 저장.
- External table : 읽기 전용 테이블. DB안에 Metadata가 저장되어 있지만, 파일은 실제로 DB 밖에 저장됨
- 테이블은 영구적(Permanent)이거나 일시적(Temporary) 함. 영구적 테이블의 정의와 데이터는 세션이 바뀌더라도 유지되지만, 임시 테이블의 정의는 세션이 바뀌어도 유지되나 데이터는 트렌섹션 이나 세션 동안 유지됨
Heap-Organized Table

Index-Organized Table
- Table-Bases Indexes
CREATE TABEL locations( id NUMBER(10) NOT NULL, description VARCHAR2(50) NOT NULL, map BLOB, CONSTRAINT pk_locations PRIMARY KEY (id) ) ORGANIZATION INDEX // Index 테이블임을 명시 TABLESPACE iot_tablespace PCTTHRESHOLD 20 // Block 사이즈 20% 넘어가면 Partitioning // Overflow 일어나면 overflow_tablespace에 넣어라 INCLUDING description OVERFLOW TABLESPACE overflow_tablespace; - Function-Based Indexes
// employees는 Table, department_id는 Column CREATE INDEX emp_depit_ix ON hr.employees(department_id); // ASC 오름차순, DESC 내림차순 CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id DESC); CREATE INDEX emp_total_sal_idx ON employees(12 * salary * commission_pet, salary, commission_pet); - Oracle은 Primary 키에 대해서는 자동으로 색인을 만들어 주지만 Foreign 키에 대해서는 자동으로 만들어주지 않음
- Index는 선택적인 구조, 테이블이나, 테이블 클러스터에서 데이터 접근 속도 빠르게 해줌
- 만약 DB에서 전체 테이블 중 작은 비율을 가지는 튜플들을 자주 요청할 경우 필요
- 색인이된 열들은 Referential integrity constraint를 만족함
- Unique key constraint도 테이블에 적용
- Heap-organiezd-table은 색인이 없으므로, DB에서 값을 찾으려면 Full scan 필요
- Index 테이블을 만드려면 Table에 Primary 키를 꼭 설정한 다음, ORGANIZATION INDEX 명령어 사용하면됨
- PCTTHRESHOLD integer : Index-organized table 행을 위해 Index block에서 예약된 공간의 퍼센티지. Primary 키 담을 수 있을 만큼은 커야함. 1~50 사이로 설정해야하고 기본 값은 50,
- INCLUDING column_name : Index-organized table 행에서 index와 overflow로 나눌 열. Primary 키 열은 무조건 index에 저장됨. column_name은 마지막 Primary 키 열이거나, 아니면 Primary 키가 아닌 열로 설정. column_name 다음의 Nonprimary 키 열들은 overflow 데이터 세그먼트 안에 들어감. 만약 column_name까지의 사이즈가 PCTTHRESHOLD에서 정의한 index의 영역보다 크다면, DB가 PCTTHRESHOLD에 따라 행을 분해함
- OVERFLOW TABLESPACE : Overflow 데이터가 저장될 테이블 명시
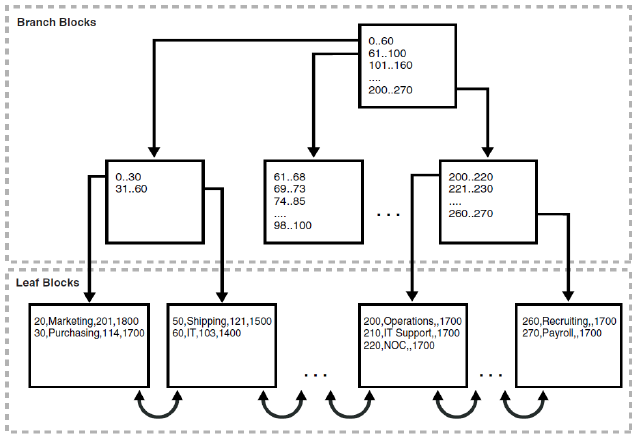
Table Clusters in Oracle
Common column을 같은 장소에 넣을 수 있게 해줌. 성능 문제로 안하는게 좋음
- 만약 Table cluster를 사용한다면 하나의 Data 블럭이 여러 테이블의 row를 가짐
- Cluster 키를 가짐, 예를 들어 employee와 department에서 department_id를 공유하는데 department_id를 Cluster 키로 둘 수 있음
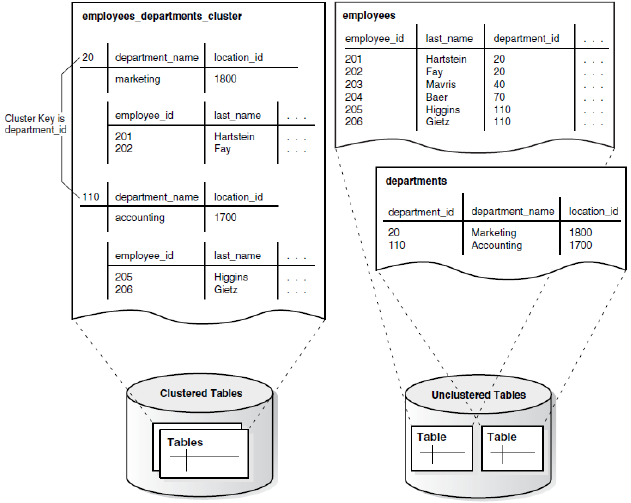
Indexed Clusters in Oracle
데이터를 찾기 위한 색인을 가진 Table cluster
- Cluster index : Cluster ket를 이용한 B-tree index
- Cluster table에 자료가 삽입되기 전에 Cluster index 만들어야함
CREATE CLUSTER employees_departments_cluster (
department_id NUMBER(4)
)
SIZE 512;
CREATE INDEX idx_emp_dept_cluster ON CLUSTER employees_departments_cluster;
이렇게 만든 후 Employee와 Department 테이블을 만든다
CREATE TABLE employees(...)
CLUSTER employees_departments_cluster(department_id);
CREATE TABLE department(...)
CLUSTER employees_departments_cluster(department_id);
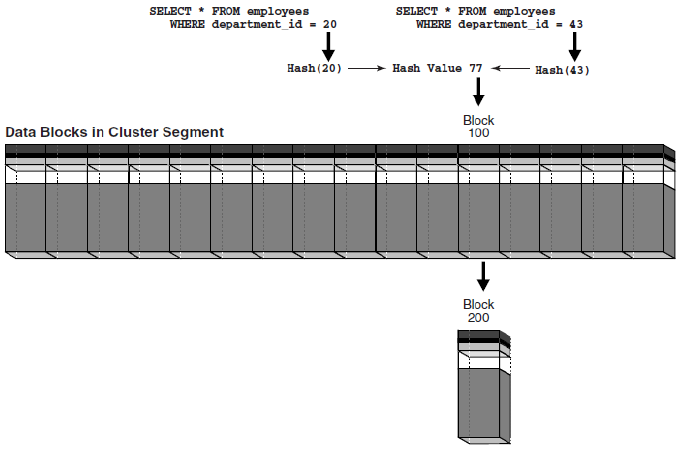
Hash Clusters in Oracle
Indexed cluster와 같지만 Index 키가 해쉬 함수로 대체됨. Hash cluster에서는 데이터가 Index가 됨
CREATE CLUSTER employees_departments_cluster(
department_id NUMBER(4)
)
SIZE 8192 HASHKEYS 100; // Hash entry 갯수
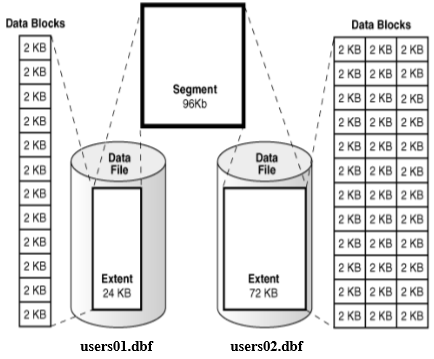
Tablespace, Segment, Extent, Oracle Data Block
Logical Storage Structures
- Oracle은 모든 데이터를 Data file에 저장
- Tablespace : 하나의 테이블이 여러 data file에 저장되는 것을 허용하기 위해, data file하나 이상으로 구성되는 tablespace라는 논리적 disk 공간 개념 제공
- 시나리오
- DBA(Database Administrator)는 여러 Tablespace들을 생성해 둠
- DBA는 각 User 계정에 대해 그 계정을 생성할 때 마다 하나의 Default tablespace 할당
- 각 사용자는 자신의 Default tablespace에 Table 생성
- 하나의 Table은 오직 하나의 Tablespace안에서 공간을 할당 받음
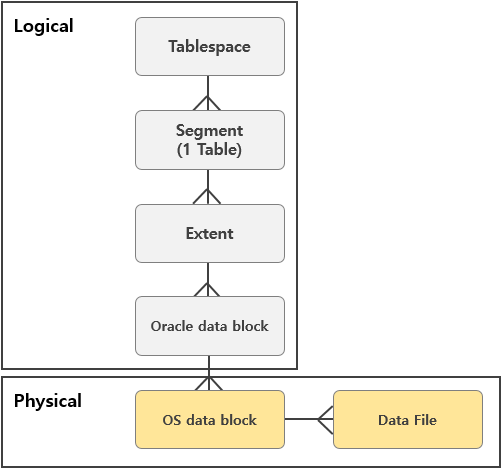
- 만약 Tablespace A에 Table B가 생성된다면 이를 Segment라 칭함 (Segment와 Table은 1:1 대응). Segment 또한 여러 개의 Data file로 구성됨
- Oracle은 하나의 Segment에 디스크 공간을 할당하고 그 Segment에서 할당 받는 단위를 Extent라 함. 하나의 Extent는 연속된 여러 개의 Oracle data block들로 구성. 하나의 Oracle data block은 여러 개의 OS data block들로 구성
- 논리적 연속성을 위해 Extent 단위로 공간 할당, 해제
- 파일 IO의 효율성을 위해 Oracle data block 사용
- 하나의 Extent는 Data file을 늘릴 수 없음
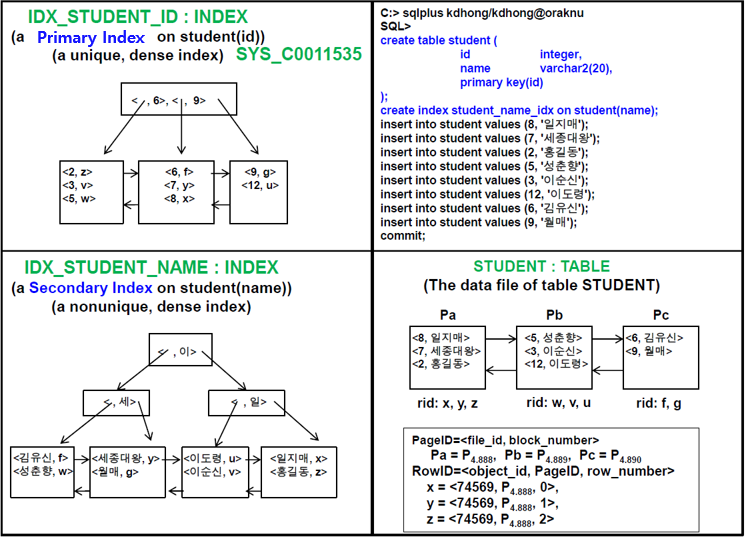
Record, Block, Data File, and Index File
- Primary 키는 자동으로 색인 생성 (Primary index)
- Secondary index는 따로 설정해 줘야함 (보조 색인)
- Block(Page) ID : File ID + Block Number
- RID (Record Identifier) : 물리적 구분자 (Object ID, Page ID, Row Number)
The Format of the Data Record
Three Record Storage Formats
- 고정된 길이 할당 (최대 길이로, DBMS는 따로 최적화 안함)
- 구분자로 구분 (동적으로 크기 변할 때)
- 구분자로 구분하고 마지막에 Terminate 기호 삽입
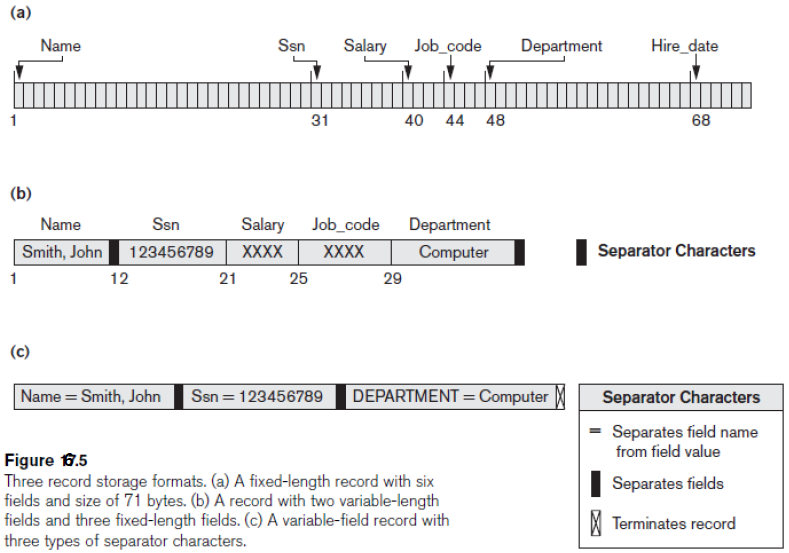
- 오라클에서는 (b) 사용, fixed_part에 오프셋 값이 있음 (몇 바이트 떨어져 있는지)
- 만약 NULL이라면 길이는 0 (앞, 위 fixed_part가 같다고 보면됨, [2][3][3][1])
- 헤더에는 NULL-bit array가 있음
- 길이는 c[i+1] - c[i]
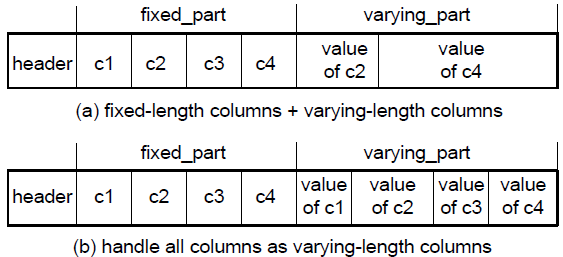
Types of Record Organization
(a) Unspanned (보통 사용) (b) Spanned
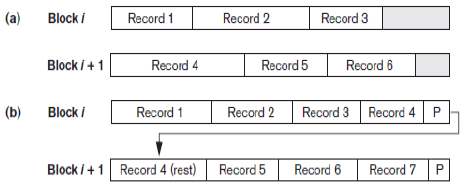
Data File에 Record를 위치시키는 방법
- Primary file organization
- 어떻게 디스크에 file records들을 넣을지, record들에 접근할지
- Heap file (순서 없음) : 순서 없이, 파일의 가장 마지막에 Record 삽입
- Sorted file (순서를 가짐) : 특정한 필드(Sort key)의 값에 따라 정렬해서 Record를 저장함
- Hashed file (해싱) : 특정 필드(Hast key)에 해쉬 함수를 적용해서 위치 특정
- B-trees
- Secondary organization (Auxiliary access structure)
- 좀 더 효율적으로 파일에 접근 가능하게 해줌 (Primary 필드 말고 다른 필드 사용해서)
Heap Files
삽입된 순서 그대로 파일에 들어감 (새로운 레코드는 파일의 가장 끝)
- Heap 또는 Pile file이라 함
- Secondary indexes를 쓰기도 함
- Insert : 그냥 끝에 넣으면 끝
- Search : 선형 검색 밖에 못함 O(N)
- Delete : Search 후 삭제, 삭제된 공간이 비어서 이럴 경우 저장 공간이 낭비됨
- Deletion marker로 삭제되었다는 것을 표시 가능
- 한번 Reorganization할 때 다 지움
- Deleteion marker가 있는 곳에 Insert해도 되지만 따로 관리 필요
- 보통 Unspanned로 관리
- 레코드의 크기가 고정되어 있으면, 연속적으로 할당되어 있을 때 접근이 쉬움
Sorted Files
- Ordering field를 기준으로 값에 따라 레코드 저장 가능 (Ordered or Sequential file) 만약 Ordering field가 파일의 Key field라면 이를 Ordering key라함
- Binary search O(logN)를 이용해 빠르게 파일 접근 가능, 레코드가 한 블럭안에 있기 때문에(레코드가 블럭 마지막이 아니라면) 다른 블럭 접근 필요 없음. 물리적 Cylinder에서도 Seek time을 적게 해줌
- 하지만 Random 접근이나, 정렬되지 않은 Field에 대해서는 마찬가지로 선형 검색 필요
- 삽입/삭제 연산이 힘듬, 삽입이나 삭제가 되더라도 물리적으로 정렬되어 있어야하기 때문, 삽입/삭제 일어난 뒤의 파일들을 모두 옮겨야함
- 사용되지 않는 공간을 표시하고 거기에 삽입을 해도 되지만, 결국 모든 공간이 사용되면 똑같음
- 보통 Temporary unordered file(Overflow/Transaction file)을 만들고 원래 파일을 Master 파일이라 부름. 새로운 레코드는 Overflow 파일의 마지막에 삽입함. 주기적으로 Reorganization을 해서 Overflow 파일을 Master 파일과 병합
- Ordered files은 DB에 가끔씩만 쓰임. Primary index를 사용해 Indexed-sequential file로 만들어서 사용. Ordering 키 필드에 대한 랜덤 접근 시간을 빠르게 해줌. Ordering attribute가 키가 아니라면 Clustered file 이라함
Hash Files
- 해싱에 기반한 파일. 특정 검색 조건에서 아주 빠른 레코드 접근을 하게 해줌
- 보통 Hash file이라 부름
- 검색 조건은 하나의 Hash field에 대한 조건과 마찬가지
- Hash field가 키라면 Hash key라고 함
- Hash 필드 값에 Hash 함수를 적용하여 파일의 주소를 알 수 있음. 대부분 경우 레코드 한 번만 보면됨
Internal Hashing
내부 파일들에 대해 해싱 적용. 보통 Hash table 사용
- 레코드의 배열을 사용해 해싱 구현
- 배열이 M개의 슬롯을 가진다면 해쉬 함수는 0 ~ M-1사이의 정수로 해쉬 필드의 값을 변환함
- 기본 : h(K) = K mod M
- Collision : 해쉬 필드 값에 이미 다른 레코드가 있을 경우
- Collision resolution : Collision 해결
- Open addressing : 빈 필드를 찾을 때까지 다음 필드의 값을 조사한 후 빈 필드에 삽입
- Overflow chaining : 오버플로우 영역에 새로운 레코드를 저장하고 링크들 리스트로 연결
- Multiple hashing : 충돌이 일어나기 전까지 해쉬 함수를 차례로 적용
External Hashing
디스크 파일들에 대해 해싱 적용
- Bucket이라면 배열 사용, Bucket에 목적지 주소 공간이 있음
- 버켓은 하나의 디스크 블럭이거나, 연결된 디스크 블럭 클러스터
- 해싱 함수를 통해 Relative bucket number를 알 수 있음
- 파일 헤더를 통해 Bucket number를 디스크 블럭 주소로 바꿔줌
- 디스크 블럭을 가리키기 때문에 한 블럭에 여러 개의 레코드가 들어갈 수 있어 Collision 문제에서 좀 더 자유로움. 만약 다 찬다면 Chaining 기법 사용. Overflow한 레코드에 대한 링크드 리스트 사용 (블럭이 아니라 레코드의 포인터). 블럭 주소와, Relative record position을 같이 가져야함
- 앞의 방법은 Static 해싱이라 버켓 M의 사이즈가 정해져 있음. Dynamic 파일들에 대해 문제점을 가짐
동적 확장이 가능한 해싱 기법
Static 해싱의 문제점 해결
- Extendible hashing
- Directory는 $2^d$의 버켓 주소를 가짐. d는 Global depth라 함. 해쉬값의 첫 d개의 비트에 해당하는 값을 통해 Directory entry를 찾음. 그리고 그 Entry가 레코드가 저장될 버켓을 정함. 디렉토리가 각각의 버켓을 가리키는 것이 아니라 여러 개의 디렉토리가 하나의 버켓을 가리킬 수도 잇음. 그리고 d’라는 Local depth도 각 버켓마다 가지는데, 버켓이 가진 요소들의 비트 갯수를 나타냄
- d가 커지거나 작아지면서, 디렉토리 배열이 가질 수 있는 Entry를 조정가능. 만약 어떤 버켓의 d’가 d와 같은 상태에서 Overflow가 일어나면 d가 두배로 커짐. 삭제 과정에서 모든 버켓의 d’이 d 보다 작다면 반으로 줄임
- Directory, Bucket 두 단계로 구성되서 간단
- 아래의 그림에서 010, 011이 가리키는 버켓에 Overflow가 일어난다면, d’가 3으로 늘어나고 두 버켓으로 나뉘게되며, 해쉬 값의 첫 비트가 010인 레코드는 010 버켓으로, 011인 레코드는 011 버켓으로 나눈다
- 만일 111 버켓에 Overflow가 생겼다면, d = d’이므로 d와 d’을 1씩늘리고 Directory 배열을 두배로 늘린 다음, 다른 Directory entity들도 두개로 나누가 같은 값으로 채워 넣음
- 파일이 많아지더라도 성능이 떨어지지 않는 장점이 있음
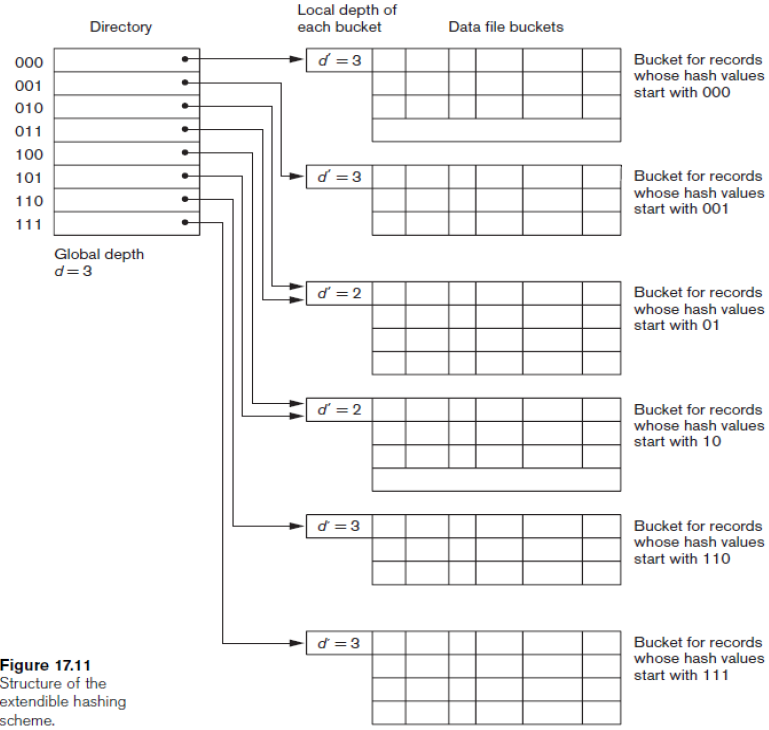
- Dynamic hashing
- Directory없이 이진 트리로 구성
- Internal nodes : 좌측 자식은 bit가 0일 경우, 우측 자식은 bit가 1일 경우
- Leaf nodes : 레코드의 버켓에 대한 포인터가 들어있음
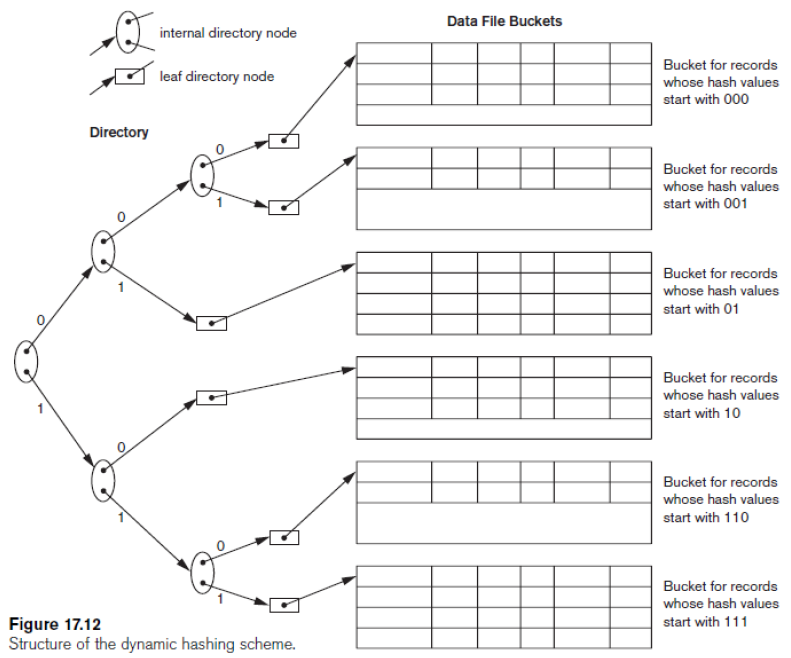
- Linear hashing
- Directory 없이 버켓의 갯수를 늘리고 줄이는 것
- 처음 버켓의 수는 M, n = 0
- $h_1(K) = K\ mod\ M$
- 각각 Overflow chaining을 함
- 만약 Overflow가 일어나면 n번째 버켓이 두개의 버켓(n, M)으로 나눠지고, 새로운 해쉬 함수 $h_2(K) = K\ mod\ 2M$이 추가되고, n = n + 1. 만약 $h_1(K) < n$이라면 $h_2(k)$를 적용.
- n이 증가해서 M과 같아졌다면, M을 두배로 키우고 n을 0으로 리셋
- youtube 참고
Database File Indexing Techniques, B-Trees, B+ - Trees
Types of Indexes
- Types of Indexes
| 물리적 순서를 위한 Index Field | 물리적 순서를 위한 것이 아닌 Index Field | |
|---|---|---|
| Index field가 Key | Primary index | Secondary index(Key) |
| Index field가 nonkey | Clustering index | Secondary index(NonKey) |
- Properties of Index Types
- Dense : 해당 키의 모든 값들을 가질 경우. 반대는 Nondense(Sparse)
| Type of Index | 첫 인덱스 엔트리 갯수 | Dense/Nondense | Block Anchoring |
|---|---|---|---|
| Primary | Data file의 Block 갯수 | Nondense | O |
| Clustering | Index field 값들의 갯수 | Nondense | O/X |
| Secondary (Key) | Data file의 레코드 갯수 | Dense | X |
| Secondary (NonKey) | 레코드 갯수이거나, Index field 값들의 갯수 | Dense/Nondense | X |
- Primary index (기본 색인) : 키 열에 대해 Data file의 레코드들을 정렬하는 색인
- Clustering index (클러스터링 색인) : 키가 아닌 열어 대해 Data file의 레코드를 정렬하는 색인
-
Secondary index (보조 색인) : Data file의 레코드를 정렬하는 것이 아니라 탐색 시 사용됨
- Ordered indexes : Primary index, Clustering index, Secondary index
-
블럭에서 첫 데이터를 Anchor record 혹은 Block anchor라고 함
- eg
- EMPLOYEE에서
- 레코드 수 r = 30000
- 레코드 크기 R = 100 byte
- 블럭 크기 B = 1024 byte
- 블럭킹 펙터 RFB = B / R = 10 레코드/블럭
- 파일 블럭수 b = r / RFB = 3000블럭
- SSN필드로 인덱스 구성한다면
- SSN크기 VSSN = 9 byte
- 레코드 포인터 P = 6 byte
- 인덱스 엔트리 크기 Ri = VSSN + P = 15 byte
- 인덱스 블럭킹 펙터 RFBi = B / Ri = 68 엔트리/블럭
- 인덱스 블록수 bi = r / RFBi = 30000 / 68 = 45블럭
- 이진 탐색 시 : $log_2(45)$ = 6블럭
- 선형 탐색 시 : b / 3000 = 1500블럭
B-Tree
- Search Tree 중 하나
- 항상 Balance(균형) 유지
- 모든 Leaf 노드들이 같은 레벨에 있음
- Underflow : 각 노드는 최소 반 이상 차있어야함
B+ - Tree
- 대부분 상용 DBMS는 B+ 트리 사용
- Tree Level은 Height - 1, Height는 실제 높이
- Internal Node
- <(P1, K1), (P2, K2), … , (Pq-1, Kq-1), Pq>
- K는 데이터 P는 자식 포인터
- Pi가 가리키는 자식은 Ki 보다 작다
- 모든 Leaf 노드는 같은 레벨에 있다
- Leaf 노드에는 Key값과 RID가 들어있다
- Leaf 노드는 이웃과 서로 Dobuly Linked List로 연결되어 있다
- Underflow : 각 노드는 최소 2/3 이상 차 있어야 함
- Key의 삽입
- 항상 Leaf node에 삽입
- 만약 Overflow가 발생하면 Split
- 노드 N을 새로 만든다
- j = ceil((P + 1) / 2)개의 엔트리는 그대로 두고 나머지는 N으로 옮긴다
- j번째 값과 N에 대한 포인터를 부모로 올린다
- 원래 노드에 Overflow가 일어난 값을 추가한다
- 부모 노드도 Overflow가 발생하면 해당 노드도 재귀적으로 Split한다
- Key 삭제
- 항상 Leaf node에서 삭제
- 만약 Underflow가 발생하면 Redistribution(재분배) 하거나 Merge(합병) 한다
- 형제 Leaf 노드를 찾아 현재 Leaf 노드와 엔트리를 재분배한다
- 재분배시 두 노드 모두 반이 이상 찰 수 없다면 형재 노드와 결합하고 Leaf 노드 수를 줄인다
- 부모 노드도 Underflow가 발생하면 재귀적으로 재분배 혹은 합병한다
- eg
- 삽입 : <8,x>, <5,y>, <1,z>, <7,w>, < 3,v>, <12,u>, <9,f>, <6,g>
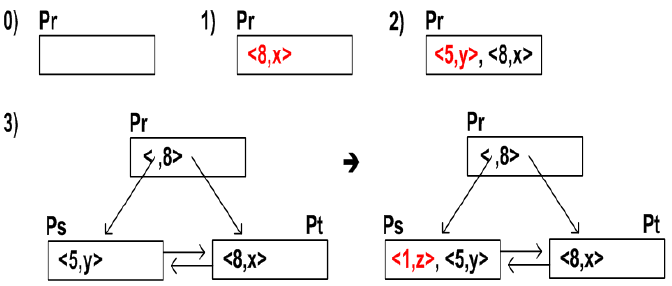
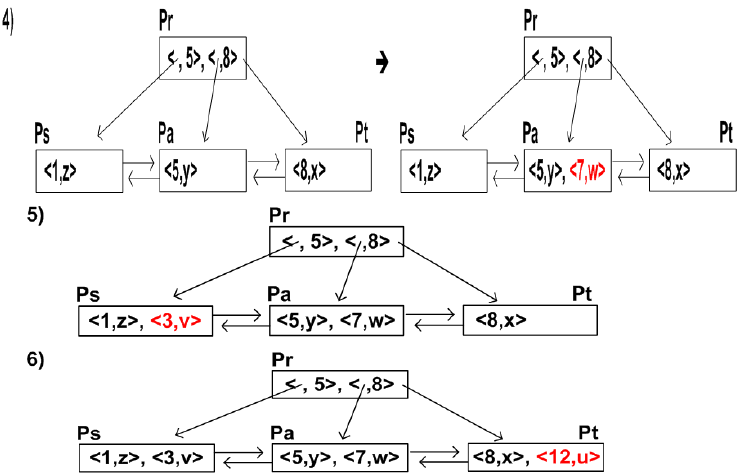
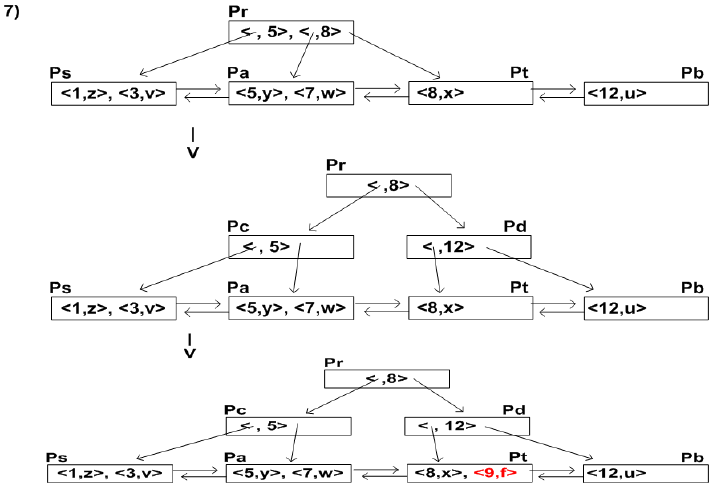
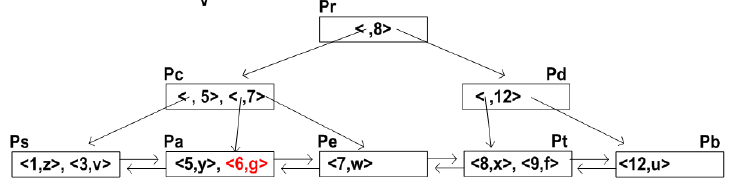
- 삭제 : <5,y>, <12,u>, <9,f>, <8,x>

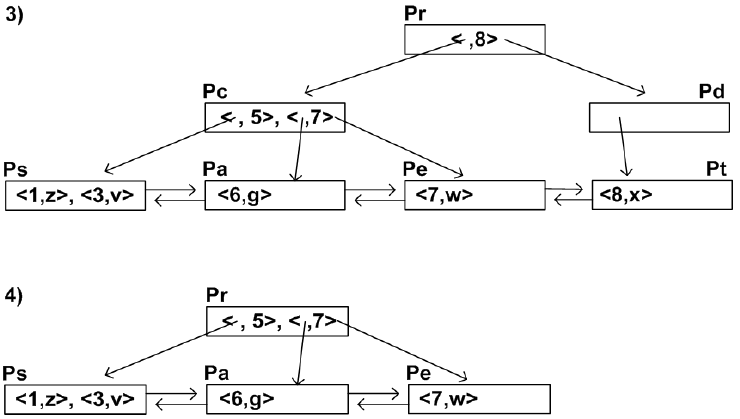
다중키 인덱스
####B+ - Tree B+와 동일하게 처리하면됨, 키가 여러 개일 뿐
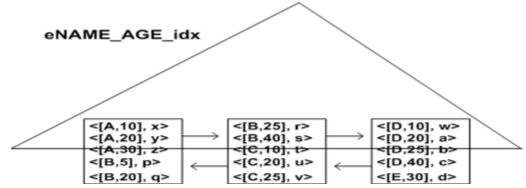
분할 해싱

그리드 파일
만약 EMPLOYEE테이블에서 DNO, AGE로 파일을 접근하고 싶다면, 그리드 배열을 만든 다음 파일에 저장해놓으면됨
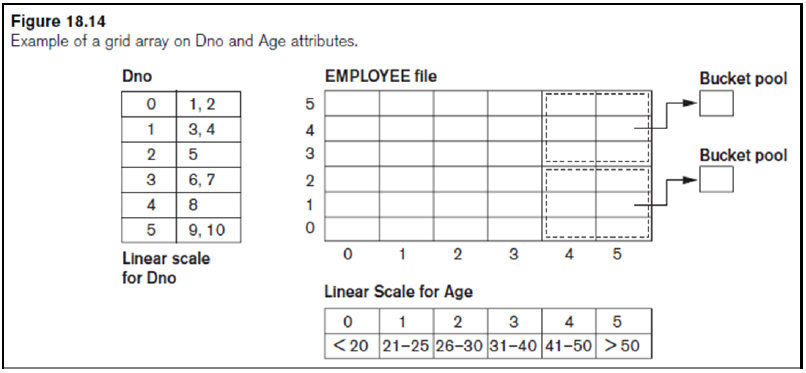
Bitmap Indexes
한 Attribute에 대해 가능한 값들을 Bit로 인덱싱 한다
- 아래 표에서 M의 경우 Row_id 순서로 M F M F F M M F 이므로 이를 1 0 1 0 0 1 1 0 으로 바꾼 것
- 예를 들어, 성별은 F 이고, Zipcode는 30022인 사람을 알고 싶다면, 01011001과 01010010에 대해 AND 연산을 하면 01010000이 되므로 2번째와 4번째 튜플을 가져오면됨
- Oracle
// EMPLOYEE 테이블의 commission Attribute에 대해 만듬 create bitmap index idx_emp_commission_bit on EMPLOYEE(commission); - 원래 B+ 트리의 경우 <Index key value, RowID>로 구성되지만, Bitmap index는 <Index key value, {Start RowID, End RowID, Bitmap엔트리}> 로 구성됨
Funstion-Based Indexing
- Oracle
CREATE INDEX upper_ix ON EMPLOYEE(UPPER(Lname)); - 아래 예시에서 구문이 조금 다르긴 하지만 자동으로 income_ix 색인을 사용함
CREATE INDEX income_ix ON EMPLOYEE(Salary + (Salary * Commission_pct)); SELECT fname, lname FROM employee WHERE((Salary * Commission_pct) + Salary) > 15000;
SQL
- 한 줄 혹은 여러줄에 기술 가능
- 탭 사용 가능
- 대소문자 구분 안함
- ;으로 종료
- SQL Buffer에 명령어 저장됨
- SQL Buffer에 저장된 명령어는 RUN 혹은 /로 실행 가능
- PL/SQL이라는 Subprogram 사용 가능 (프로그램 같은 SQL)
DECLARE x NUMBER := 100; BEGIN FOR i IN 1..10 LOOP IF MOD (i, 2) = 0 THEN INSERT INTO temp VALUES(i, x, 'i is even'); ELSE INSERT INTO temp VALUES(i, x, 'i is odd'); END IF; x := = X + 100; END LOOP; END; /
Data Types
Character
| 자료형 | 형식 | 설명 |
|---|---|---|
| CHAR | CHAR(size) | 고정 길이 문자열, 정한 사이즈 보다 작은 값을 넣으면 Blank로 패딩됨, 정한 사이즈 보다 크면 Oracle이 에러를 냄, 최소 1 byte에서 최대 2000 byte까지 가능, size는 기본적으로 Byte qualifier라 몇 byte인지 넣게됨, CHAR qualifier도 넣을 수 있는데 (eg)CHAR(10 CHAR))) 보통 CHAR qualifier의 경우 1 ~ 4 byte임 |
| NCHAR | NCHAR(size CHAR) | Unicode-only 데이터타입. DB에서 쓰일 문자셋 확장에 사용. 최대 2000 byte. NCHAR에 CHAR 넣는 것 불가, 반대도 마찬가지 |
| VARCHAR | VARCHAR는 사용하지 말 것 (VARCHAR2와 같음), Oracle 11g 이후에는 내부에서 VARCHAR2로 자동 변환 | |
| VARCHAR2 | VARCHAR2(size [BYTE, CHAR]) | 가변 문자열. 최대 4000 byte. size는 최대 사이즈를 말함 |
| NVARCHAR2 | NVARCHAR2(size CHAR) | NCHAR의 가변 버전 |
| 함수 | 형식 | 설명 |
|---|---|---|
| length | length(문자열) | 문자열의 Character 수 반환, 문자열이 NULL일 경우 아무것도 반환 안함 |
| lengthb | lengthb(문자열) | 문자열의 Byte 수 반환, 문자열이 NULL일 경우 아무것도 반환 안함 |
| replace | replace(문자열, 대상, 바꿀값) | 대상과 같은 문자를 바꿈 |
| trim | trim(문자열) | 문자열 끝의 모든 공백 제거 |
- Orcacle에서 CHAR, VARCHAR2 자료형에서 ‘‘을 NULL로 취급, 그렇기 때문에 IS NULL 옵션으로 찾아야함
SELECT t.id FROM student t WHERE t.name IS NULL;
Number
| 자료형 | 형식 | 설명 |
|---|---|---|
| NUMBER | NUMBER(p) | p자리 수 |
| NUMBER | NUMBER(p,s) | Significant decimal digits 갯수 p, 소숫점 아래 s자리 수 |
| INT | INT | NUMBER(38)과 동일 |
| 데이터 | 자료형 | 실제 저장 |
|---|---|---|
| 123.89 | NUMBER | 123.89 |
| 123.89 | NUMBER(3) | 124 |
| 123.89 | NUMBER(6, 2) | 123.89 |
| 123.89 | NUMBER(6, 1) | 123.9 |
| 123.89 | NUMBER(3, 2) | Exceeds precision |
| 123.89 | NUMBER(4, 2) | Exceeds precision |
| 123.89 | NUMBER(6, -2) | 100 |
| .00012 | NUMBER(4, 5) | 0.00012 |
| .000127 | NUMBER(4, 5) | 0.00013 |
| .00000123 | NUMBER(2, 7) | 0.0000012 |
| 함수 | 형식 | 설명 |
|---|---|---|
| round | round(수, 소수점) | 반올림 |
| trunc | trunc(수, 소수점) | 내림 |
Date
| 자료형 | 형식 | 설명 |
|---|---|---|
| DATE | DATE | 날짜와 시간 정보 모두 저장 가능. 7 byte 고정 길이 |
| TIMESTAMP | TIMESTAMP | millisecond까지 보관 |
| 포멧 | 설명 |
|---|---|
| MM | 숫자 월 (07) |
| MON | 단축 월 이름 (JUL) |
| MONTH | 월 이름 (JULY) |
| DD | 날짜 (24) |
| DY | 요일 (FRI) |
| YYYY | 4자리 년도 (1998) |
| YY | 마지막 2자리 년도 (98) |
| RR | 1950 ~ 2049년 사이로 반올림, 06의 경우 2006이 됨 |
| AM(PM) | 오전, 오후 표시 |
| HH | 1-12시 |
| HH24 | 0-23시 |
| MI | 분 (0-59) |
| SS | 초 (0-59) |
| FF | 밀리초, 최대 6자리, FFn이면 n자리 |
| 함수 | 형식 | 설명 |
|---|---|---|
| to_char | to_char(date, ‘format’) | DATE를 문자열로 바꿈 |
| to_date | to_datea(string, ‘format’) | 문자열을 DATE로 바꿈 |
| to_timestamp | to_timestamp(string, ‘format’) | 문자열을 TIMESTAMP로 바꿈 |
| +/- | date +/- n | n일 더함. n은 Float으로 1/24라면 한 시간이 더해지는 거고, 1/(24*60) 이면 1분이 더해지는 것 |
| - | date - date | 날짜에 날짜를 뺌, + 연산은 불가능함 |
| trunc | trunc(date, ‘format’) | format에 맞게 버림. trunc(SYSDATE, ‘MI’)의 경우 초가 버려짐 |
| last_day | last_day(date) | date 달의 마지막 날의 현재 시각 |
| next_day | next_day(date, ‘일’) | date 이후 첫 일요일의 현재 시각 |
| month_between | month_between(date1, date2) | date1에서 date2 사이의 달을 Float으로 알려줌. 한 달이면 1 |
| INTERVAL | INERVAL string DAY TO SECOND | string에 해당하는 날 만큼 TIMESTAMP단위(밀리초)로 바꾼다 |
- Oracle 기본 포맷 ‘RR/MM/DD’
- SYSDATE로 현재 시간 알 수 있음
- SYSTIMESTAMP를 통해 현재 시간의 밀리초까지 알 수 있음
- TIMESTAMP도 초단위까지는 +/- 연산이 가능하지만, Millisecond를 계산하려면 INTERVAL 키워드 사용
alter session set NLS_DATE_FORMAT='format'으로 기본 포멧 변경 가능- date Attribute 추가 시나 select 시 string을 그대로 넣으면 안되고 꼭 to_date로 변환 후 넣어야함
ROWID
각 행마다 주소가 있고 이를 ROWID라 함
- Heap-organiezd table은 ROWID(물리적 ROWID) 존재. pseudocolumn ROWID를 쿼리해 알 수 있고, 문자열이며, 해당 문자열의 데이터 타입은 ROWID임
- 다음과 같은 정보를 가짐
- Data file의 Data block은 Row를 가짐. 이 문자열의 길이는 OS에 따라 결정됨
- Data block 안의 Row
- DB file도 Row를 가짐. 첫 Data file은 1. 길이는 OS에 따라 다름
- 모든 DB Segment마다 고유하게 Data object number를 가짐. USER_OBJECTS, DBA_OBJECTS, ALL_OBJECTS dictionary view로 Data object number를 알 수 있음. 같은 Segment에 포함되는 객체는 같은 Data object number를 가짐
- A-Z, a-z, 0-9, +, /로 이루어짐
- 바로 사용할 수는 없고 DBMS_ROWID 패키지를 이용해야함
- 오라클은 UROWID(Universal ROWID)를 Index-organized, Foreign table의 주소를 위해 사용함. Index-organized table은 Logical UROWID를 가지며 Foreign table은 Foreign UROWID를 가짐. 둘 다 ROWID pseudocolumn에 들어 있음
- 오라클은 Primary 키를 이용해 Logical ROWID 생성. Primary 키가 바뀌지 않는 이상 Logical ROWID는 바뀌지 않음. Logical ROWID의 데이터 타입은 UROWID
- 오라클 B+ 트리의 리프노드에 실제로 저장되는 ROWID는 10 byte 크기. 하지만 출력되는 ROWID는 18자리의 포맷
SELECT id, name, ROWID, LENGTH(ROWID) FROM emp_f order by id;
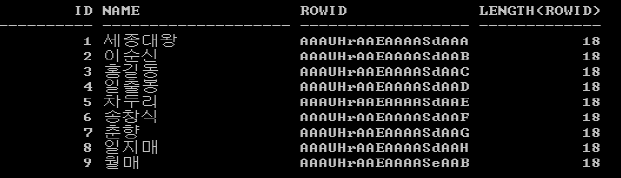
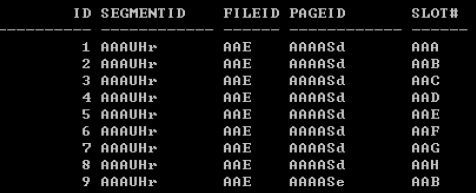
- Data object number (세그먼트 식별) : SUBSTR(ROWID, 1, 6)
- File ID (테이블스페이스 내 상대적 File 번호) : SUBSTR(ROWID, 7, 3)
- Page ID (데이터 파일 내 상대적 Block 번호) : SUBSTR(ROWID, 10, 6)
- slot# (Block 내 각 row 번호) : SUBSTR(ROWID, 16, 3)
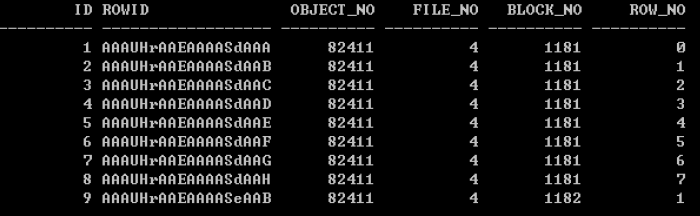
- dbms_rowid 패키지 이용 출력
SELECT id, ROWID,
dbms_rowid.rowid_object(rowid) object_no,
dbms_rowid.rowid_relative_fno(rowid) file_no,
dbms_rowid.rowid_block_number(rowid) block_no,
dbms_rowid.rowid_row_number(rowid) row_no
FROM emp_f;
Statements
SQL Statements
| 종류 | Statement |
|---|---|
| Session Management (Client-Server Connection) | CONNECT TO, DISCONNECT |
| Data Retrieval | SELECT |
| DML (Data Manipulation Language) | INSERT, UPDATE, DELETE, TRUNCATE, MERGE |
| DDL (Data Definition Language): SCHEMA, USER, TABLE, INDEX, VIEW, TYPE, PRODEDURE, FUNCTION | CREATE, ALTER, DROP, RENAME |
| Transaction Control | COMMIT, SAVEPOINT, ROLLBACK |
| DCL (Data Control Language) | GRANT, REVOKE |
- ALTER : 변경
ALTER USER user_name IDENTIFIED BY new_password; // QUOTA는 사용하고자하는 테이블 스페이스 전체 용량 중 사용자가 사용할 수 있는 양 지정 ALTER USER user QUOTA 0 ON USERS; - DROP : 삭제
// CASCADE는 사용자가 접속하지 않았을 때 사용자의 모든 데이터베이스 스키마 삭제 DROP USER user_name [CASCADE]; - GRANT : 권한 부여
GRANT connect, resource TO user; - REVOKE : 권한 삭제
REVOKE UNLIMITED TABLESPACE FROM user; - 유저 생성 및 삭제
// 사용자 생성 CREATE USER user1 IDENTIFIED BY user11; // 권한 부여 GRANT resource, connect TO user1; GRANT dba TO user1; // 기본 테이블스페이스 설정 ALTER USER user1 DEFAULT TABLESPACE USERS; ALTER USER user1 TEMPORARY TABLESPACE TEMP; // 사용자 삭제 DROP USER user1 CASCADE;
Tables
Relational Table과 Object Table
오라클에서 테이블은 Relational Table과 Object Table로 나뉨
- Relational Table
CREAE TABLE employees( employee_id NUMBER(6), first_name VARCHAR2(20), last_name VARCHAR2(25) CONSTRAINT emp_last_name_nn NOT NULL, email VARCHAR(25) CONSTRAINT emp_email_nn NOT NULL, salary NUMBER(8, 2), department_id NUMBER(4), CONSTRAINT emp_salary_min CHECK (salary > 0), CONSTRAINT emp_email_uk UNIQUE (email) ) ALTER TABLE employees ADD ( CONSTRAINT emp_emp_id_pk PRIMARY KEY (employee_id), CONSTRAINT emp_dept_fk FOREIGN KEY (department_id) REFERENCES departments ); - Object Table
- 객체 타입, C++에서 클래스 만드는 것과 비슷
CREATE TYPE dept_typ AS OBJECT( d_name VARCHAR2(100), d_address VARCHAR2(200) ); CREATE TABLE dept_obj OF dept_typ; INSERT INTO dept_obj VALUES('HR', '10 Main St,CA');
- 객체 타입, C++에서 클래스 만드는 것과 비슷
- Heap-organiezd table
- Non-partitioned table
- Partitioned table
- Clustered table
- Temporary table
CREATE GLOBAL TEMPORARY TABLE table_name {ON COMMIT DELETE ROWS | ON COMMIT PRESERVE ROWS} AS select_stmt;- ON COMMIT DELETE ROWS 옵션은 Transaction 종료 시 row가 삭제됨
- ON COMMIT PRESERVE ROWS 옵션은 Session 종료 시 row가 삭제됨
- Session이 종료하여도 Table은 그대로 남기 때문에 처리해줘야함
TRUNCATE TABLE table_name; DROP TABLE table_name;
- Table cluster, Indexed cluster
- Hash Clusters in Oracle
*
CREATE TABLE
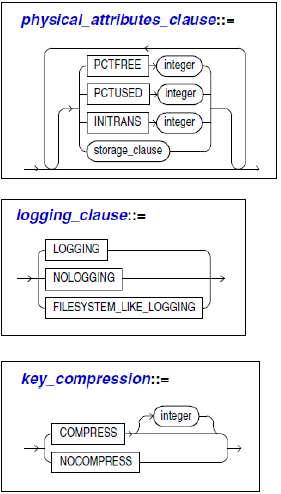
- 테이블 생성 시 TABLESPACE 속성 부여 가능
CREATE TABLE table(...) TABLESPACE USERS; - 테이블 생성 시 PCTFREE, PCTUSED 속성 부여 가능
CREATE TABLE table(...) PCTFREE = 10, PCTUSED = 40;- 블럭 b가 처음 할당되면, Free Block 상태
- 오라클은 Free Block 상태의 블럭에만 새로운 레코드 입력 가능
- Free Block상태에서 블럭 내 Free space가 PCTFREE% 이상인 경우 Free Block 상태가 유지되고, PCTFREE% 미만이 되면 Full Block 상태가됨
- Full Block상태에서 블럭이 DELETE 또는 UPDATE에 의해 Used space가 PCTUSED%이하가 되면 Free Block 상태가됨
*
FOREIGN KEY
FOREIGN KEY (referencing_column) REFERENCES referenced_table [(referenced_column)] [ON DELETE { CASCADE | SET NULL | SET DEFAULT | NO ACTION | RESTRICT }] [ON UPDATE { CASCADE | SET NULL | SET DEFAULT | NO ACTION | RESTRICT }]Referential action
- RESTRICT : 피참조 테이블에서 삭제, 수정되려는 행을 참조 테이블에서 참조하고 있으면 오류
- NO ACTION : 피참조 테이블에서 삭제, 수정 후, 참조 테이블에서 무결성 제약 조건을 위배하면 오류
- CASCADE : 피참조 테이블에서 삭제, 수정 후, 참조 테이블에서 무결성 제약 조건에 따라 삭제 또는 수정
- SET NULL : 피참조 테이블에서 삭제, 수정 후, 참조 테이블에서 무결성 제약 조건에 따라 NULL로 바꿈. 만약 NOT NULL 옵션이 붙었다면 오류
- SET DEFAULT : 피참조 테이블에서 삭제, 수정 후, 참조 테이블에서 무결성 제약조건에 따라 Default 값으로 바꿈. Default값이 없으면 NULL. Default값 없으면서 NOT NULL이면 오류
DROP TABLE statement

- 테이블을 DROP하게 된다면
- 모든 행들이 Drop됨
- 모든 테이블 색인과, 도메일 색인이 Drop됨, Trigger도 마찬가지, 만약 Partitioned 됐다면 Local index partition들도 Drop
- Nested 테이블의 Storage 테이블과, 테이블의 LOBs도 Drop
- Range-, Hash-, List-partitioned 테이블을 Drop하면 DB의 모든 Table Partition들도 Drop. Composte-partitioned 테이블을 Drop한다면 모든 Partition과 Subpartition들도 Drop
- CASCADE CONSTRAINTS
- Primary, Foreign 키듷에 대한 모든 Referential integrity constraints를 Drop 한다. 만약 이 옵션을 넣지 않는다면 참조 무결성 조건에 의해 오류가 발생
- PURGE
- 한 번에 테이블을 Drop 시키면서 테이블에 연관된 공간을 해제하려면 PURGE 옵션 사용. PURGE 옵션을 사용한다면 DB는 쓰레기통(Recycle bin)에 넣지 않고 바로 지움. Rollback 불가
DROP TABLE department CASCADE CONSTRAINTS; DROP TABLE emp PURGE;
- 한 번에 테이블을 Drop 시키면서 테이블에 연관된 공간을 해제하려면 PURGE 옵션 사용. PURGE 옵션을 사용한다면 DB는 쓰레기통(Recycle bin)에 넣지 않고 바로 지움. Rollback 불가
Table Management
- 열 추가
ALTER TABLE emp ADD job VARCHAR(12);- emp 테이블에 job이라는 새로운 열을 추가함
- emp 각 튜플에 대해 job이라는 Attribute의 값을 입력해야함 (Default나 Update로)
- Default 지정 않는다면, 명령 실행 후 모두 NULL로 채워지므로 NOT NULL 제약 조건 사용 불가
- 열 삭제
ALTER TABLE emp DROP COLUMN address CASCADE;- CASCADE : 열과 함께 열을 참조하는 모든 제약 조건과 뷰들을 스키마로부터 자동 제거
- RESTRICT : 그 열을 참조하는 뷰들과 제약 조건이 없어야만 제거 가능
- 열 수정
ALTER TABLE emp ALTER COLUMN mgr_ssn DROP DEFAULT; ALTER TABLE emp ALTER COLUMN mgr_ssn SET DEFAULT '3334455'; ALTER TABLE emp ADD CONSTRAINT dno_fk FOREIGN KEY (dno) REFERENCES dept(dept_no); ALTER TABLE emp DROP CONSTRAINT empsuperfk CACADE; - Check Constraint
CREATE TABLE divisions( div_no NUMBER CONSTRAINT check_div_no CHECK(div_no BETWEEN 10 AND 99) DISABLE ); ALTER TABLE divisions ENABLE CONSTRAINT check_div_no; CREATE TABLE dept_20 ( salary NUMBER(7, 2), CONSTRAINT check_sal CHECK(salary > 0) );- 오라클에서 자동으로 체킹함
- Table 생성과 Foreign 키 설정 순서 유의해야함
Index Management
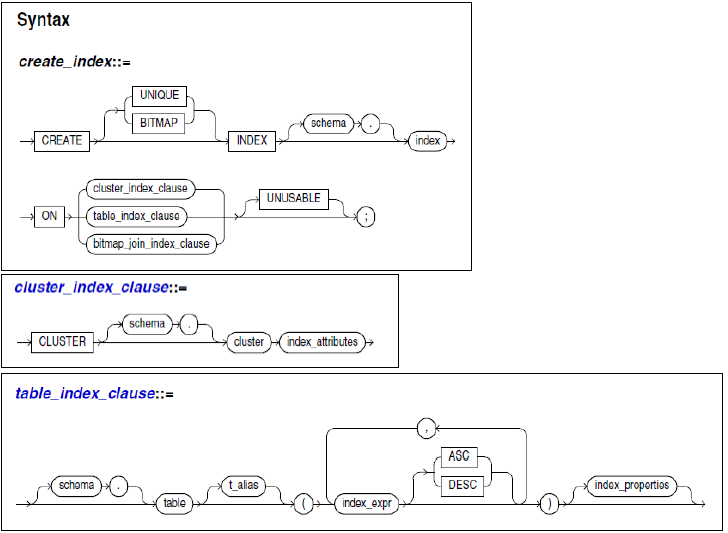
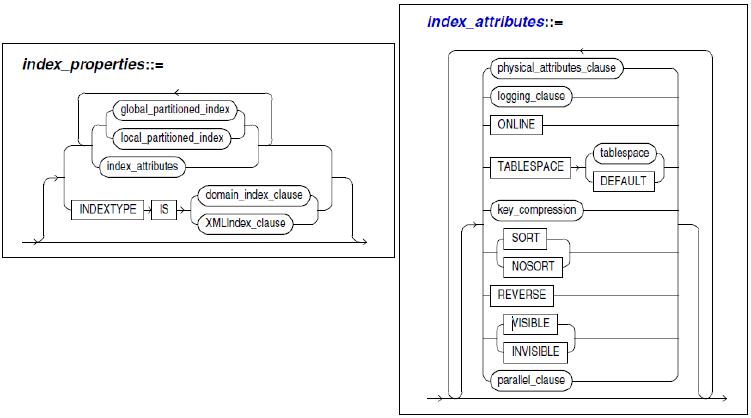
- 색인과 표준
- SQL 초기에는 기본 릴레이션의 Attribute 대상으로 인덱스를 생성하고 제거하는 문이 있었지만, 인덱스는 논리적 개념이 아닌 물리적 접근 경로이기 때문에 SQL2에서 이 문을 제거
- 색인 생성
CREATE INDEX lname_index ON emp(lname); CREATE INDEX names_index ON emp(lname ASC, fname DESC, minit); CREATE UNIQUE INDEX ssn_index ON emp(ssn); CREATE INDEX dno_index ON CLUSTER personnel; // Table cluster에 대한 Index - 색인 삭제
DROP INDEX dno_index; - 함수 기반 색인
CREATE INDEX emp_total_sal_index ON emp(12 * salary * commission_pct, salary, commission_pct); - 오라클에서 색인
Partitioned Table / Partitioned Index
- Partitoned Table
- Partitioning(파티셔닝)은 대용량 DB Object들을 여러 조각으로 분할하여 관리
- Partion : Partitioned object가 갖는 분할된 조각
- Sharding : DB Object를 나눌 때 Row 기준으로 나누는 것. Partition은 Row나 Column 상관 없이 나눔
- Partioned object를 사용하더라도, 사용하지 않은 것과 마찬가지로 쿼리, DML등 SQL문을 동일하게 사용 가능
- Non-partitioned 테이블은 하나의 Tablespace만을 이용함
- Partitioned 테이블은 Table 파티션 별로 각각의 Tablespace 지정 가능
- Partitioned 테이블은 일반 테이블과 동일하지만 보관 주기 관리, 성능 향상 등 대용량 DB에서는 중요
- Partioned Table 종류 및 특징
- Range Partition (범위 파티션) : 테이블 파티션을 VALUES LESS THAN으로 구분하여 해당 범위 만족하는 레코드들을 한 파티션에 저장
- List Partition (리스트 파티션) : 테이블 파티션을 VALUES로 구분하여 동일 값의 레코도들을 한 파티션에 저장
-
Hash Partition (해쉬 파티션) : 테이블 파티션을 Hash로 구분하여 동일한 해쉬 값을 가지는 레코드들을 한 파티션에 저장
-
특징
항목 Range List Hash 추가(ADD) X X O 병합(COALESCE) X X O 삭제(DROP) O O X 합병(MERGE) O O X 이름 변경(RENAME) O O O 분할(SPLIT) O O X 레코드 삭제(TRUNCATE) O O O
- Partitioned Table에 대한 연산
- 추가
ALTER TABLE part_table ADD PARTITION part_5;- Hash 파티션만 ADD PARTITION 가능, 추가하게 되면 모든 파티션 재구성
- Range, List 파티션은
SPLIT PARTITION으로 나눠야함
- 병합
ALTER TABLE part_table COALESCE PARTITION;- Hash 파티션에서 마지막 파티션만 삭제되고 그 파티션의 데이터가 기존 데이터와 함께 다시 파티션 테이블이 재구성됨. 무조건 마지막 것 부터 삭제
- 삭제
ALTER TABLE part_table DROP PARTITION part_5;- 파티션 테이블에서 특정 파티션 삭제. List, Range 파티션만 가능
- 예를 들어 과거 데이터에 대한 삭제를 쉽게 할 수 있음
- 합병
ALTER TABLE part_table MERGE PARTITION part_4, part_5 INTO part_5;- 두 개의 파티션을 하나의 파티션으로 합침. List, Range 파티션 만 가능
- In-place merge : 새로운 파티션이 생성될 Tablespace를 지정하지 않고 기존 파티션과 이름이 같을 경우
- Out-place merge : 새로운 파티션이 추가로 생성되어 기존의 파티션 레코들이 새로운 파티션으로 복사되거나, 새로운 파티션의 이름이 기존 파티션과 같더라도 새로운 Tablespace를 지정해줄 경우
- 이름 변경
ALTER TABLE part_table RENAME PARTITION part_5 TO part_6- Range, List, Hash 모두 가능
- 분할
ALTER TABLE part_table SPLIT PARTITION part_5 AT (TO_DATE(‘2006/03/01’)) INTO (PARTITION part_6, PARTITION part_5);- Range, List 가능
- 위의 예시에서 part_5를 2006/03/01 기준으로 part_6과 5로 나눔
- 레코드 삭제
ALTER TABLE part_table TRUNCATE PARTITION part_5;- 해당하는 파티션의 데이터는 모두 지우고 파티션 정의는 그대로 유지
- 추가
- 예제
아래 Range 파티션1의 SALES_DATE를 Partition Key Column이라함
// Range 파티션1 CREATE TABLE PART_TABLE ( SALES_DATE DATE, SALES_ID NUMBER, SALES_CITY VARCHAR2(20) ) PARTITION BY RANGE (SALES_DATE) ( PARTITION PART_1 VALUES LESS THAN (to_date('2011/02/01','YYYY/MM/DD')) TABLESPACE pts_02, PARTITION PART_2 VALUES LESS THAN (to_date('2011/03/01','YYYY/MM/DD')) TABLESPACE pts_03, PARTITION PART_3 VALUES LESS THAN (to_date('2011/04/01','YYYY/MM/DD')) TABLESPACE pts_04, PARTITION PART_DEF VALUES DEFALUT tablespace pts_max ); // Range 파티션2 CREATE TABLE PART_TABLE ( SALES_DATE DATE, SALES_ID NUMBER, SALES_CITY VARCHAR2(20) ) PARTITION BY RANGE (SALES_DATE, SALES_ID) ( PARTITION PART_1 VALUES LESS THAN (to_date('2011/02/01','YYYY/MM/DD'), 200), PARTITION PART_2 VALUES LESS THAN (to_date('2011/03/01','YYYY/MM/DD'), 100), PARTITION PART_3 VALUES LESS THAN (to_date('2011/03/01','YYYY/MM/DD'), 200), PARTITION PART_4 VALUES LESS THAN (to_date('2011/04/01','YYYY/MM/DD'), 100), PARTITION PART_DEF VALUES DEFALUT ) TABLESPACE SYS_TBS_DISK_DATA; // List 파티션 CREATE TABLE PART_TABLE ( SALES_DATE DATE, SALES_ID NUMBER, SALES_CITY VARCHAR2(20) ) PARTITION BY LIST (SALES_CITY) ( PARTITION PART_1 VALUES ('SEOUL', 'INCHEON'), PARTITION PART_2 VALUES ('BUSAN', 'JEJU'), PARTITION PART_3 VALUES ('CHUNGJU', 'DAEJUN'), PARTITION PART_DEF VALUES DEFALUT ) TABLESPACE SYS_TBS_DISK_DATA; // Hash 파티션 CREATE TABLE PART_TABLE ( SALES_DATE DATE, SALES_ID NUMBER, SALES_CITY VARCHAR2(20) ) PARTITION BY HASH (SALES_ID) ( PARTITION PART_1, PARTITION PART_2, PARTITION PART_3, PARTITION PART_4 ) TABLESPACE SYS_TBS_DISK_DATA; - Partitioned Index
- Partitioned Table에 생성하는 Index를 Partitioned Index라 함
- 두 가지 생성 가능
- Partitioned index : Partitioned table에 대한 색인도 파티션으로 구성할 경우
- Non-partitioned index : Partitioned table에 대해 색인은 파티션으로 구성하지 않을 경우
- Partitioned table에서는 Partitioned index를 생성하면 성능과 관리에 유리
- Partitioned Index
- 구조로 분류 (관리)
- Local index : Index의 각 파티션과 테이블의 각 파티션이 1:1 관계에 있는 경우. Partitioned table 구조와 Partitioned index 구조가 동일
- Global index : Index의 각 파티션과 테이블의 모든 파티션이 데이터와 관련 있는 경우. Partitioned tabel과 Partitioned index 구조가 다름
- Indexing column으로 분류 (성능)
- Prefix index : Indexing column들의 첫 Column이 Index partition key의 첫 Column과 동일한 경우
- Non-prefix index : Prefix index가 아닌 경우
- 구조로 분류 (관리)
- Local and Prefix Index
Index IDX_P4만 이용해서 찾음
CREATE TABLE PART_TABLE ( SALES_DATE DATE, SALES_ID NUMBER, SALES_CITY VARCHAR2(20) ) PARTITION BY RANGE (SALES_DATE) ( PARTITION P1 VALUES LESS THAN (to_date('2011/02/01','YYYY/MM/DD')), PARTITION P2 VALUES LESS THAN (to_date('2011/03/01','YYYY/MM/DD')), PARTITION P3 VALUES LESS THAN (to_date('2011/04/01','YYYY/MM/DD')), PARTITION P4 VALUES LESS THAN (to_date('2011/05/01','YYYY/MM/DD')), PARTITION P5 VALUES DEFAULT ) TABLESPACE SYS_TBS_DISK_DATA; CREATE INDEX idx_local ON part_table(sales_date) LOCAL // Oracle에서 LOCAL을 생략하면 GLOBAL INDEX이다. ( PARTITION IDX_P1 ON P1, PARTITION IDX_P2 ON P2, PARTITION IDX_P3 ON P3, PARTITION IDX_P4 ON P4, PARTITION IDX_P5 ON P5 ); SELECT * FROM PART_TABLE WHERE SALES_DATE = to_date('2011/04/01','YYYY/MM/DD'); - Local and Non-prefix Index
IDX_P1부터 P6까지 다 찾아봐야함
CREATE TABLE PART_TABLE ( SALES_DATE DATE, SALES_ID NUMBER, SALES_CITY VARCHAR2(20) ) PARTITION BY RANGE (SALES_DATE) ( PARTITION P1 VALUES LESS THAN (to_date('2011/02/01','YYYY/MM/DD')), PARTITION P2 VALUES LESS THAN (to_date('2011/03/01','YYYY/MM/DD')), PARTITION P3 VALUES LESS THAN (to_date('2011/04/01','YYYY/MM/DD')), PARTITION P4 VALUES LESS THAN (to_date('2011/05/01','YYYY/MM/DD')), PARTITION P5 VALUES DEFAULT ) TABLESPACE SYS_TBS_DISK_DATA; CREATE INDEX IDX_LOCAL ON PART_TABLE(SALES_ID) LOCAL ( PARTITION IDX_P1 ON P1, PARTITION IDX_P2 ON P2, PARTITION IDX_P3 ON P3, PARTITION IDX_P4 ON P4, PARTITION IDX_P5 ON P5 ); SELECT * FROM PART_TABLE WHERE SALES_ID = 6;
Insert
- 테이블에 튜플을 추가
- 튜플값들의 순서는 CREATE TABLE에서 명시한 순서와 같아야 함
- Attribute 값을 임의로 명시 가능, 명시 하지 않은 Attribute들은 Default 혹은 NULL
-
Subquery이용 가능
// Subquery INSERT INTO emp(eid, enma, did, start_date) VALUES(90, '홍길동', (SELECT did FROM dept_t WHERE dnma='자재'), SYSDATE);
Delete
- 테이블에서 튜플을 제거
- 조건은 WHERE 절에 명시
- 한 번에 한 테이블 내의 튜플들만 삭제 가능
- WHERE 생략 시 테이블 내의 모든 튜플 삭제
-
Subquery이용 가능
DELETE FROM emp; DELETE FROM emp WHERE lname='Brown'; DELETE FROM emp WHERE dno IN (SELECT dnumber FROM dept WHERE dname='Research');
Update
- 튜플들의 Attribute 값 수정
- WHERE로 한 테이블안에서 수정할 튜플들 선택 가능
- SET으로 변경할 Attribute들과 새로운 값 지정
-
Subquery이용 가능
UPDATE project SET plocation='Bellaire', dnum=5 WHERE pnumber=10; UPDATE emp SET salary = salary * 1.1 WHERE dno IN (SELECT dnumber FROM dept WHERE dname='Research');
Update / Delete 참조 행동
SELECT
SELECT [ALL | DISTINCT] <target_list>
[INTO <host_var_list>]
FROM <table>
[WHERE <condition>]
[GROUP BY <grouping_attribute> [HAVING <grouping_condition]]
[ORDER BY <attributes>]
[LIMIT { count[OFFSET offset] | offset, count}]
- LIMIT는 ANSI 표준은 아니지만 오라클, MySQL등에서 가능
- ORDER BY가 명시되지 않았으면 순서가 없음
SELECT 실행 순서
FROMWHEREGROUP BYHAVINGSELECTORDER BYLIMITWHERE절에서는FROM의 Attribute들만 알 수 있음JOIN연산 후SELECT구문 처리
```
SELECT bdate, address
FROM emp
WHERE fname='John' AND minit='B' AND lname='Smith';
SELECT e.bdate, e.address
FROM emp e
WHERE e.fname='John' AND e.minit='B' AND e.lname='Smith';
```
NULL / Three-Valued Logic (3VL)
잃어버린 정보를 처리하기 위해 NULL을 도입
- 없다는 마킹을 하기 위해 NULL
- NULL과 비교 연산을 하면 True나 False가 아닌 Unknown이 결과로 나옴
- 3VL = True, False, Unknown
- NULL인가 아닌가 따로 구분을 위해 IS NULL, IS NOT NULL 구문(Predicate)을 만듬
- SQL에서 WHERE구문은 결과가 True인 것만 반환
| AND | TRUE | FALSE | UNKNOWN |
|---|---|---|---|
| TRUE | TRUE | FALSE | UNKNOWN |
| FALSE | FALSE | FALSE | FALSE |
| UNKNOWN | UNKNOWN | FALSE | UNKNOWN |
| OR | TRUE | FALSE | UNKNOWN |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| FALSE | TRUE | FALSE | UNKNOWN |
| UNKNOWN | TRUE | UNKNOWN | UNKNOWN |
| = | TRUE | FALSE | UNKNOWN |
|---|---|---|---|
| TRUE | TRUE | FALSE | UNKNOWN |
| FALSE | FALSE | TRUE | UNKNOWN |
| UNKNOWN | UNKNOWN | UNKNOWN | UNKNOWN |
| NOT | |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| UNKNOWN | UNKNOWN |
연산자
- 사용 가능 연산자
- 산술 연산자 : +, -, *, /, %
- 관계 연산자 : =, !=, <>, >, >=, <, <=, like (String match)
- 논리 연산자 : IN, NOT, BETWEEN a AND b, AND, OR
-
문자열 연산자 : (Concatenation) -
비트 연산자 : «, », &,
- LIKE
- 부분 문자열 비교도 가능
- ’%’ 임의의 개수의 문자
- ‘_’ 임의의 한 문자
// 주소에 Houston,TX를 포함하는 종업원 검색 SELECT fname FROM emp WHERE address LIKE '%Houston,TX%';
구문
- Subquery
- Inline view :
FROM절에 Subquery가 있을 경우 - Nested subquery :
WHERE,SELECT,HAVING절에 Subquery가 있을 경우-
Correlated subquery : 외부 질의에 선언된 Table 중 어떤 Column을 참조할 경우
SELECT salary FROM emp e WHERE salary > (SELECT AVG(salary) FROM emp k WHERE k.dno = e.dno); -
Uncorrelated subquery : 외부 질의에 선언된 Table 중 어떠한 Column도 참조하지 않을 경우
SELECT ename, title FROM emp WHERE title = (SELECT title FROM emp WHERE ename='홍길동');
-
- Inline view :
- TRUNCATE
- 테이블에서 모든 데이터를 지우는 가장 빠른 방법
-
Tuple variable : 테이블 변수라고 생각하면 됨. 아래 예시의 e
SELECT e.lname FROM emp e; -
* : SELECT * 는 모든 Attribute들을 결과로 냄
// *(Asterisk)는 모든 Attribute 출력해줌 SELECT * FROM emp WHERE fname='John' AND minit='B' AND lname='Smith'; -
DISTINCT : 질의 결과를 집합으로 (중복 튜플 없애줌)
// DISTINCT는 결과를 집합으로 (중복된 요소 없애줌) SELECT DISTINCT * FROM emp; -
IN : 외부 질의의 한 튜플이 괄호 안에 있는 튜플 집합의 원소가 되는지. 파이썬의 in과 같음
// 명시적 집합 및 IN SELECT * FROM emp WHERE name IN ('Park', 'Kim'); - ANY(SOME) : 하나의 값이 집합 내 어떤 한 값과 같으면 참
- ALL : 하나의 값이 집합 내 모든 값과 같으면 참
- EXISTS(Q) : Q에 최소 하나의 튜플이 있다면 참
-
UNIQUE(Q) : Q에 중복된 튜플이 없다면 참
SELECT * FROM emp WHERE dno = ANY (SELECT dept_no FROM dept WHERE rank > 10); SELECT * FROM emp WHERE dno > ALL (SELECT dept_no FROM dept WHERE rank > 10); - ORDER BY : 하나 이상의 Attribute들로 질의의 결과 튜플 정렬
- ORDER BY n : n은 양의 정수. SELECT문의
중 n 번째 기준 정렬 - ASC : 오름차순
- DESC : 내림차순
- 오라클에서는 NULL을 최대값으로 출력 (
DESC NULLS FIRST,DESC NULLS LAST옵션 가능)
// ORDER BY SELECT lname FROM emp WHERE ssn >= 10 ORDER BY ssn; // 여기서는 2번째 Column(AVG(salary)) 순으로 정렬 SELECT dept_num, AVG(salary), COUNT(dept_num) FROM emp GROUP BY dept_num ORDER BY 2;SELECT a, b, c FROM m;a b c 3 5 7 4 2 6 5 3 2 SELECT b, c FROM m ORDER BY a, b;b c 5 7 2 6 3 2 - ORDER BY n : n은 양의 정수. SELECT문의
- GROUP BY
- 쿼리 결과를 그룹으로 묶어줌
GROUP BY의 Attribute들은SELECT구문에도 등장해야함
SELECT dno, COUNT(*), AVG(salary) FROM emp GROUP BY dno HAVING AVG(salary) >= 1000;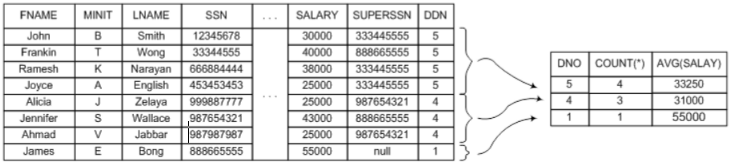
- COUNT : 지정한 튜플, 값들의 개수 반환
- MAX : 최대값
- CHAR, VARCHAR2, NUMBER, DATE 가능
- MIN : 최소값
- CHAR, VARCHAR2, NUMBER, DATE 가능
- SUM : NULL 제외한 값들의 합
- NUMBER 가능
- AVG : NULL 제외한 평균값 (나눌 때도 NULL 개수는 제외)
- NUMBER 가능
- VARIANCE : NULL 제외한 분산
- NUMBER 가능
- STDDEV : NULL 제외한 표준편차
- NUMBER 가능
SELECT SUM(salary), MAX(salary), MIN(salary), AVG(salary), COUNT(*) FROM emp WHERE dnumber = 10;SELECT college_no, dept_no, job, count(*), ABG(salary), SUM(salary) FROM emp GROUP BY college_no, dep_no, job;COLLEGE_NO DEPT_NO JOB COUNT(*) AVG(SALARY) SUM(SALARY) 10 30 PROFESSOR 10 1000 10000 10 30 CLERK 2 400 800 10 40 PROFESSOR 12 1000 12000 10 40 CLERK 3 500 1500 20 50 PROFESSOR 4 1200 4800 20 50 CLERK 1 600 600 -
Conditional Results
SELECT e.eid, e.ename CASE e.eid WHEN 10 THEN ' is a good person' WHEN 20 THEN ' is a nice guy' WHEN 30 THEN ' is a wonderful person' WHEN 40 THEN ' is a superman' ELSE NULL END description FROM emp e ORDER BY e.eid;|EID|ENAME|DESCRIPTION| |–|–|–| |10|John|is a good person| |20|Kim|is a nice guy| |30|Cate|is a wonderful person| |40|Michael|is a superman| |50|Lucy||
-
Rename
SELECT * FROM (SELECT eid, ename FROM emp WHERE eid > 30) emp_rename; SELECT emp_rename.eid, emp_rename.ename FROM (SELECT eid, ename FROM emp WHERE eid > 30) emp_rename; SELECT emp_rename.eid AS id, emp_rename.ename AS name FROM (SELECT eid, ename FROM emp WHERE eid > 30) emp_rename; SELECT eid AS id, ename AS name FROM (SELECT eid, ename FROM emp WHERE eid > 30) emp_rename; - JOIN
-
CROSS PRODUCT
SELECT * FROM emp, dept; SELECT ssn, dname FROM emp, dept; SELECT * FROM emp, dept WHERE dnmae = 'Research' AND dno=dnumber -
INNER JOIN
SELECT lname FROM (emp JOIN dept ON dno = dnumber) WHERE dname = 'Research'; -
LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN
OUTER키워드 생략 가능SELECT e.lname AS emp name, s.lname AS supervisor name FROM (emp e LEFT OUTER JOIN emp s ON e.superssn = s.ssn);
-
- Funtions
UPPER: 대문자로LENGTH: 길이ABS: 절댓값
- Rownum
- Pseudo-column (의사 열)
- MySQL은 지원하지 않음
SELECT * FROM proj;PROJ_NO PROJ_NAME DEPT_NO 10 첫과제 20 30 두과제 20 40 세과제 SELECT * FROM proj WHERE ROWNUM <= 2;PROJ_NO PROJ_NAME DEPT_NO 10 첫과제 20 30 두과제 20 - MERGE
- 두 테이블을 하나의 테이블로 합침
CREATE TABLE A ( id number primary key, name varchar2(20) ); INSERT INTO A VALUES (1,'one'); INSERT INTO A VALUES (3,'three'); INSERT INTO A VALUES (5,'five'); commit;CREATE TABLE B ( id number primary key, name varchar2(20) ); INSERT INTO B VALUES (2,'TWO'); INSERT INTO B VALUES (3,'THREE'); commit;MERGE INTO A d USING B s ON (s.id = d.id) WHEN MATCHED THEN UPDATE set d.name = s.name WHEN NOT MATCHED THEN INSERT (id, name) VALUES (s.id, s.name);
Compound query
UNION, INTERSECTION, EXCEPT(MINUS)를 사용하는 쿼리
- 집합 연산의 결과는 집합 (중복된 튜플 제거됨)
- UNION : 합집합
- INTERSECTION : 교집합
- EXCEPT(MINUS) : 차집합
- UNION ALL : 합집합 이지만 중복 허용
Temporary Table
- Inline view
- FROM 절의 Subquery
- SQL 실행 동안만 임시 정의
- Explicit(명시적) 임시 테이블
SELECT문에서WITH절 사용- DB2, Oracle에서만 지원 (MySQL X)
- 해당 질의 내에서만 유효
with cust (custId integer, custName varchar(20)) as ( select cust.id, cust.name from Customer cust ), custPorder (custId integer, poId integer, poAcct varchar(20), poDate varchar(10)) as ( select cust.id, po.id, po.acctId, po.date from cust, Porder po where cust.custid = po.custId ) select custpo.custId, custpo.poId, custpo.poDate, item.id, item.info from Item item, custPorder custpo where item.poId = custpo.poId; - 오라클
CREATE GLOBAL TEMPORARY TABLE table_name { ON COMMIT { DELETE ROWS | PRESERVE ROWS } } AS select_stmt; - SQLite, MySQL
- Session 종료 시 까지 테이블과 튜플들 유지
CREATE TEMPORARY TABLE table_name (..); CREATE TEMPORARY TABLE table_name AS SELECT * FROM emp;
VIEWS
VIEW 기본
- VIEW : 다른 테이블로 부터 유도된 하나의 테이블
- 이때 다른 테이블은 Base table 혹은 Previously defined views 가 될 수 있음
- VIEW는 물리적으로 존재하는 테이블이 아닌 가상 테이블. Base 테이블은 물리적으로 존재
- VIEW에 업데이트는 불가능하지만 다른 모든 쿼리문은 가능함
- VIEW는 쿼리를 간단하게 만들어줌
- 보안/인증용 매커니즘으로 VIEW를 사용하기도함
VIEW 생성
CREATE [OR REPLACE] [FORCE | NOFORCE] VIEW view_name[(alias[,alias]...)]
AS subquery
[WITH CHECK OPTION]
[WITH READ ONLY];
- OR REPLACE : 같은 이름의 뷰가 있을 경우 다시 생성
- FORCE : 기본 테이블 관계 없이 뷰 생성
- NOFORCE : 기본 테이블 있을 때만 뷰 생성
- ALIAS : 기본 테이블의 Attribute이름과 다르게 지정한 뷰의 Attribute이름 지정
- WITH CHECK OPTION : 뷰에 의해 접근 가능한 행(튜플)만이 삽입, 수정 가능
-
WITH READ ONLY : DML 작업 제한
- 뷰 정의 시에는
ORDER BY불가능 OR REPLACE로 뷰의 정의 변경 (ALTER로 변경하는 것이 아님)- 뷰의 연산은 기존 테이블 연산과 동일
VIEW 삭제
DROP VEIW view_name;
-
예
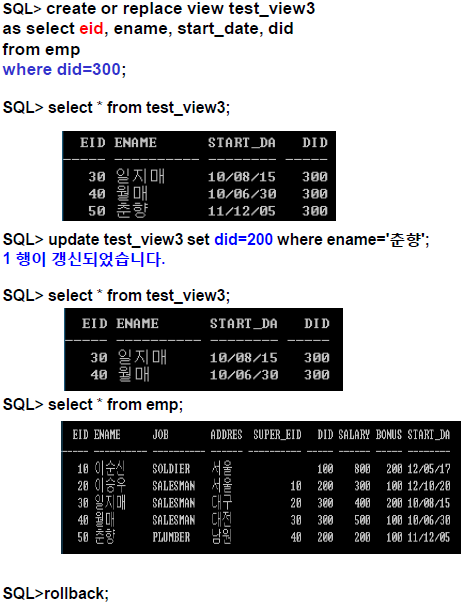
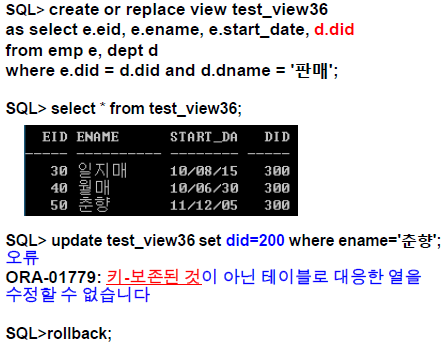
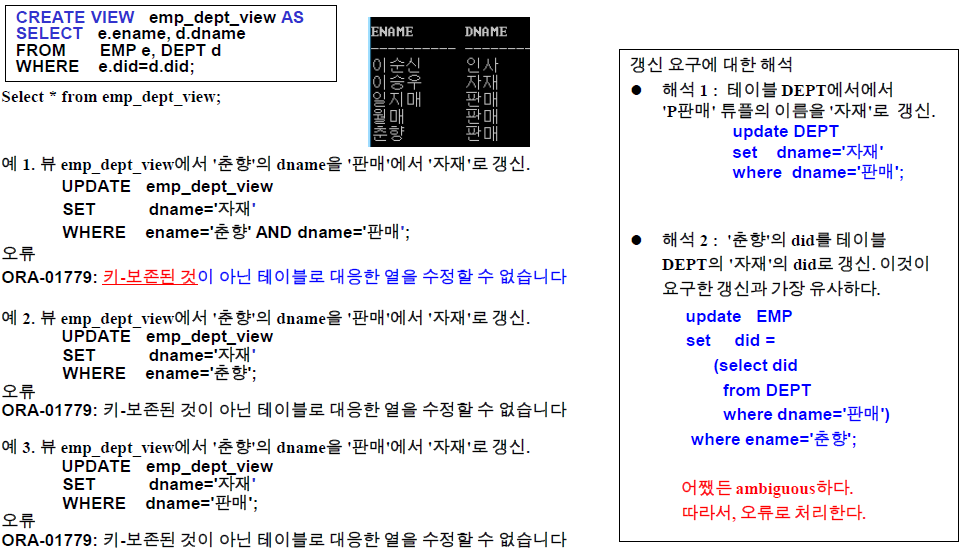
CREATE OR REPLACE VIEW did300_view AS SELECT ename, job, salary, did FROM emp WHERE did=300;SELECT * FROM did300_view;ENAME JOB SALARY DID John SALESMAN 400 300 Cate SALESMAN 500 300 Kim PLUMBER 200 300 SELECT ename, dname FROM did300_view e, dept d WHERE e.did = d.did;ENAME DNAME John 판매 Cate 판매 Kim 판매 SELECT view_name, text FROM user_views WHERE view_name = 'did300_view';VIEW_NAME TEXT DID300_VIEW SELECT ename, job, salary, did FROM emp WHERE did=300; DESCRIBE did300_view;이름 널? 유형 ENAME VARCHAR2(20) JOB VARCHAR2(20) SALARY NUMBER(38) DID NUMBER(38)
VIEW 업데이트
- 복잡, 불분명
- 보통, Aggregation 함수 없이 하나의 테이블에 대해 정의된 뷰라면, 특정한 조건을 가지고 기본 테이블을 업데이트하는 것과 같은 효과
JOIN을 가진 뷰라면, 일반적으로는 갱신 불가- 뷰에 대한 갱신은, 하나의 기본 테이블에 대한 갱신일 경우만 갱신이 가능하다
- 뷰에 대한 갱신이 여러 테이블에 대한 갱신으로 맵핑된다면 더 명확하게 특정 필요
-
하나의 기본 테이블을 기초로하는 단순 뷰일 경우 아래 조건 제외하고는
DELETE,UPDATE,INSERT가능삭제 불가 수정 불가 추가 불가 그룹 함수(SUM, MAX 등) 그룹 함수 그룹함수 GROUP BY GROUP BY GROUP BY DISTINCT DISTINCT DISTINCT ROWNUM ROWNUM ROWNUM Expression으로 정의된 Column Expression으로 정의된 Column 뷰에 의해 선택되지 않은 NOT NULL Column이 기본 테이블에 존재 시
Transaction
트랜젝션은 작업의 완전성을 보장해준다. 이 말은 작업들이 모두 완벽하게 처리되었거나, 혹은 아무것도 처리되지 않은 효과를 내준다.
Life Cycle
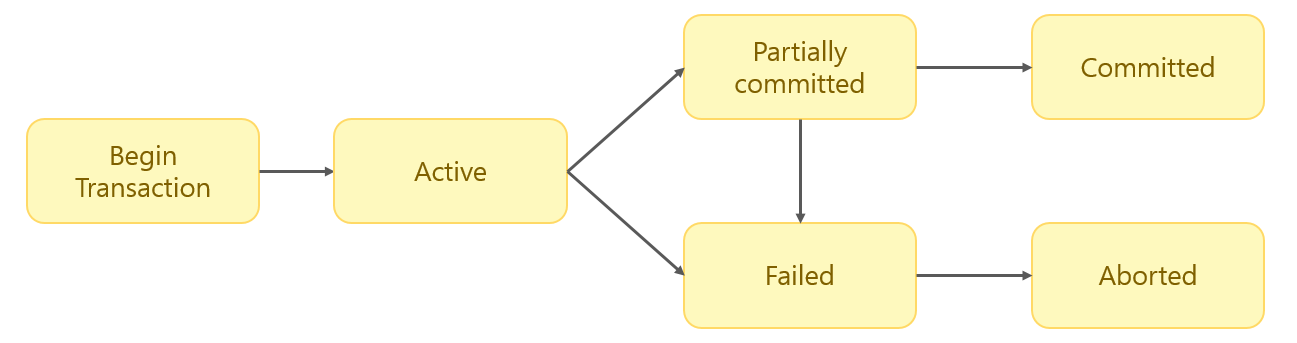
- Active : 트랜젝션이 실행중
- Failed : 트랜젝션이 실패함
- Partial committed : Commit 명령이 도착해
commit이전sql구문이 실행된 상태 - Committed : 트랜젝션이 문제 없이 커밋된 상태
- Aborted : 트랜젝션이 취소된 상태. 트랜젝션 이전 상태로 돌아간다
SELECT … FOR UPDATE
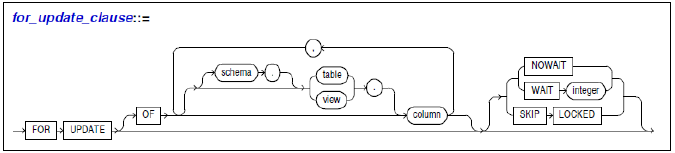
-
Update를 하기 위해 Select를 하는 경우. 해당 튜플들에 LOCK을 검
SELECT * FROM emp WHERE eid = 20 FOR UPDATE; SELECT * FROM emp e WHERE e.eid = 20 FOR UPDATE OF e.ename, e.salary; - NOWAIT
- 바로 LOCK을 잡을 수 없다면 오류
SELECT * FROM emp WHERE eid = 20 FOR UPDATE NOWAIT; - WAIT n
- 바로 LOCK을 잡을 수 없다면 지정한 n초 만큼 기다림
SELECT * FROM emp WHERE eid = 20 FOR UPDATE WAIT 5;
Transaction Management
- Transaction의 시작
- COMMIT, ROLLBACK으로 끝나는 SQL 구문 다음에 Transaction 시작
- 묵시적 시작
- BEGIN [WORK] 처럼 명시적 시작을 알리는 DBMS도 존재
- Transaction의 종료
- COMMIT [WORK] : 완료. 현재 Transaction을 성공적으로 끝냄
- ROLLBACK [WORK] : 전역복귀. 현재 Transaction을 취소
COMMIT,ROLLBACK,DISCONNECTION으로 Transaction 종료
- SAVEPOINT savepoint_name;
- Transaction내에서 정의. 다음에 Rollback 가능하게 저장
- ROLLBACK [WORK] TO [SAVEPOINT savepoint_name];
- 부분 복귀
-
다음에 수행할 Transaction의 속성 정의
SET TRANSACTION transaction_mode [{, transaction_mode}...]; transaction_mode := ISOLATION LEVEL level_of_isolation | transaction_access_mode | DIAGNOSTICS SIZE number_of_conditions level_of_isolation := READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE transaction_access_mode := READ ONLY | READ WRITE number_of_conditions := simple_value_specification격리도 Dirty read Non-repeatable read Phantom read Oracle 지원 READ UNCOMMITTED O O O X READ COMMITTED X O O O (default) REPEATABLE READ X X O X SERIALIZABLE X X X O - Dirty read : 다른 세션에서 커밋하기전 수정한 데이터도 읽을 수 있음
- Non-repeatable read : 한 트렌잭션에서 작업 도중, 다른 세션에서 작업중인 값을 바꾸어 원래 결과와 상이한 결과가 나오는 경우
- Phantom read : 유령 읽기 라고도함. 한 트랜잭션에서 여러 번 읽기를 진행했을 때 다른 세션에서 테이블에 레코드를 추가하여 원래 쿼리에 없던 레코드가 새롭게 나타날 경우
- Transaction-level read consisteny
- 그 Transactin의 모든 질의는 그 Transaction 시작 전에 Commit한 data만을 봄
- Autocommit
-
SET AUTOCOMMIT { ON OFF }; - Autocommit 활성화 시 매 DML마다 자동으로 Commit함. SQL *Plus에서는 기본값 OFF
- Transaction 중 exit/quit 하면 Commit
- Transaction 중 수행 창 제거하면 Rollback
-
-
COMMIT/ROLLBACK
SELECT * FROM emp; INSERT INTO emp(id, name) VALUES (10, 'John'); COMMIT; SELECT * FROM emp; INSERT INTO emp(id, name) VALUES (20, 'KIM'); ROLLBACK;UPDATE emp SET salary=700 WHERE eid=20; SAVEPOINT sal_20; /* Some commits */ ROLLBACK TO SAVEPOINT sal_20;


Privilege
용어
- Identification(식별) : 사용자 구분 (ID)
- Autentication(인증) : 식별(ID) + 유효한지(Password)
- Privilege(권한)
- System 권한 : 특정 SQL문을 실행할 수 있게 하는 권한
- Object 권한 : 어떤 객체(테이블, 뷰, 시퀀스 등)에 대한 접근 권한
- Authorization(인가) : 특정 사용자가 특정 자원을 사용할 수 있게 권한 부여
사용자 생성/변경/삭제
-
사용자 생성
CREATE USER user_name IDENTIFIED [ BY password | EXTERNALLY ] [ DEFAULT TABLESPACE tablespace_name ] [ TEMPORARY TABLESPACE temp_tablespace_name ] [ QUOTA [ {integer [ K | M ] } | UNLIMITED ]] ON tabelspace_name ] [ PASSWORD EXPIRE ] [ ACCOUNT [ LOCK | UNLOCK ]] [ PROFILE [ profile | DEFAULT ]] -
암호 변경
ALTER USER user_name IDENTIFIED BY new_password; -
사용자 삭제
- CASCADE : 사용자 이름과 관련된 모든 DB 스키마 삭제, 스키마 객체들도 삭제. 현재 접속중인 사용자는 삭제 불가
DROP USER user_name [CASCADE];
권한
System 권한
- PUBLIC으로 권한 부여 시 취소할 때도 PUBLIC으로
-
GRANT … TO …
시스템 권한 유형 허락되는 연산 CREATE SESSION 세션 DB에 연결할 수 있는 권한 CREATE USER 사용자 사용자 생성할 수 있는 권한 CREATE TABLE 테이블 사요자 소유 스키마 안에서 테이블 또는 인덱스 생성 권한 CREATE SEQUENCE 시퀀스 시퀀스 생성 권한 CREATE VIEW 뷰 뷰 생성 권한 ALTER USER 사용자 사용자 정의 변경 권한 DROP UPSER 사용자 사용자 삭제 권한 CREATE SYNONYM SYNONYM Private Synonym 생성 권한 -
사용자 권한 보기
SELECT * FROM dba_sys_privs WHERE grantee='John'; -
DBA는 GRANT문을 이용해 사용자에게 권한 부여
GRANT [ system_privilege_name | role_name ] TO [ user_name | role_name | PUBLIC ] [ WITH ADMIN OPTION ]- system_privilege_name : 시스템 권한 이름
- role_name : 권한을 부여할 DB 역할 이름
- user_name, role_name : 권한 부여할 유저, DB 역할의 이름
- PUBLIC : 모든 사용자에게 부여
- WITH ADMIN OPTION : 권한을 부여 받은 사용자도 부여 받은 권한을 다른 사용자에게 부여 가능
-
시스템 권한 취소
REVOKE [ system_privilege_name | role_name ] FROM [ user_name | role_name | PUBLIC ]- WITH ADMIN OPTION 절로 인해 권한이 부여 받은 사용자에게 권한을 부여 받은 사용자들까지 권한이 취소되지는 않음. Cascade 안됨
Object 권한
-
GRANT … ON … TO …
객체 권한 Table View Sequence ALTER O DELETE O O EXECUTE INDEX O INSERT O O REFERENCES O SELECT O O O UPDATE O O -
객체 권한 부여
GRANT [ object_privilege_name | ALL ] ([ column_name ]) ON [ schema_name. ] object_name TO [ user_name | role_name | PUBLIC ] [ WITH GRANT OPTION ]object_privilege_name: 부여할 객체 권한 이름ALL: ON 절 뒤의 object로 지정된 객체 존재하는 모든 객체 권한 부여column_name: 객체 권한을 부여할 테이블 또는 뷰의 ColumnINSERT,UPDATE,REFERENCES객체 권한의 경우만
object_name: 객체 명user_name, role_name : 권한을 부여할 사용자 이름, DB 역할 이름PUBLIC: 모든 사용자에게 권한 부여WITH GRANT OPTION: 객체 권한을 부여 받은 사용자도 다른 사용자에게 권한을 줄 수 있음
GRANT select ON emp TO jhh, kd; GRANT select, update(id, name) ON emp TO jhh, kd; GRANT ALL ON jhh.emp TO kd; - 객체 권한 조회
-
관리자용
데이터 사전 뷰 설명 dba_tab_privs DB 객테의 모든 권한 dba_col_privs 객체의 Column에 지정된 모든 권한 SELECT * FROM dba_tab_privs WHERE owner = 'jhh'; SELECT * FROM dba_col_privs; -
일반 사용자용
데이터 사전 뷰 설명 user_tab_privs 객체 권한 소유자, 부여자, 피부여자의 객체 권한 뷰 user_tab_privs_made 사용자가 소유주인 모든 객체 권한 뷰 user_tab_privs_recd 객체 권한 피부여자인 사용자를 위한 객체 권한 뷰 user_col_privs 객체 권한 소유자, 부여자, 피부여자의 Column의 객체 권한 뷰 user_col_privs_made 사용자 소유 객체 Column에 대한 모든 객체 권한 user_col_privs_recd 객체 권한 피부여자인 사용자를 위한 Column의 객체 권한 뷰 SELECT * FROM user_tab_privs_recd WHERE owner='jhh'; -
모든 사용자용
데이터 사전 뷰 설명 all_tab_privs 사용자 또는 PUBLIC으로 부여된 객체 권한 뷰 all_tab_privs_made 각 사용자의 권한과 사용자 소유 객체의 권한 뷰 all_tab_privs_recd 사용자 또는 PUBLIC으로 주어진 객체에 대한 권한 뷰 table_privileges 사용자 객체 권한의 소유자, 부여자, 피부여자 이거나 PUBLIC으로 부여된 객체 권한 뷰 all_col_privs 사용자 또는 PUBLIC으로 부여된 Column 객체 권한 뷰 all_col_privs_made 사용자가 사용자 또는 권한 부여자인 Column 객체 권한의 뷰 all_col_privs_rece 사용자가 피부여자이거나 또는 PUBLIC으로 부여된 Column 객체 권한의 뷰 column_privileges 사용자가 객체 권한의 소유자, 부여자, 피부여자이거나 PUBLIC으로 부여된 Column 객체 권한 뷰 SELECT * FROM all_tab_privs_made WHERE grantor = 'jhh';
-
-
객체 권한 취소
REVOKE object_privilege_name ON [ schema_name. ] object_name FROM [ user_name | role_name | PUBLIC ] [ CASCADE CONSTRAINTS ]- 객체 권한 취소는 권한 부여자만 수행 가능
PUBLIC: 객체 권한을 부여 받은 모든 사용자 권한 취소CASCADE CONSTRAINTS: References 객체 권한에서 사용된 참조 무결성 제약을 같이 삭제WITH GRANT OPTION으로 객체 권한을 부여 받은 사용자가 객체 권한을 취소당하면, 해당 사용자가 부여한 객체 권한도 함께 취소
롤(Role)
- 사용자에게 부여할 권한들의 집합. 이름을 가짐
- 하나의 사용자는 다수의 롤을 부여 받을 수 있음
-
사용자에게 권한 부여, 관리, 취소 용이
-
롤 생성
CREATE ROLE role_name [ NOT IDENTIFIED | IDENTIFIED BY [ password | EXTERNALLY ]]role_name: 생성할 역할 이름NOT_IDENTIFIED: 역할을 활성화시킬 때 인증 작업 필요 없음-
IDENTIFIED BY: 비밀번호 제공하거나EXTERNALLY로 정의된 OS상에서 인증 작업 수행 -
대표적인 롤
롤 내용 CONNECT 일반 사용자용 롤. DB 접속, 테이블과 뷰의 생성 등 기본 권한 RESOURCE 개발자용 롤. 프로시저, 트리거의 생성, 무제한 테이블 영역 사용. CONNECT롤과 같이 사용되어야함DBA DB 관리자용 롤. ADMIN OPTION이 있는 모든 시스템 권한 - Oracle 설치 시 기본적으로 위의 세 롤이 제공
- 롤 부여 / 취소
- 부여와 취소는 다른 권한과 마찬가지로 GRANT, REVOKE사용
CREATE ROLE db_manager; GRANT create session, create table, create view TO db_manager; GRANT db_manager TO park, system_manager; -
롤 변경
ALTER ROLE role_name [ NOT IDENTIFIED | IDENTIFIED BY [ password | EXTERNALLY ]];ALTER ROLE db_manager IDENTIFIED BY scott; -
롤 데이터 사전 뷰
데이터 사전 뷰 설명 role_sys_privs 롤에 부여도니 시스템 권한에 대한 뷰 role_tab_privs 권한에 부여된 테이블 권한에 대한 뷰 role_role_privs 다른 권한에 부여된 롤 뷰 session_roles 사용자가 현재 가능한 권한에 대한 뷰 user_role_privs 현재 사용자가 접근 할 수 있는 롤에 대한 뷰 dba_sys_privs 사용자와 롤에 부여된 시스템 권한 뷰 dba_roles DB에 존재하는 모든 롤에 대한 뷰
동의어(Synonym)
- 객체에 다른 이름을 붙여 사용
- Synonym을 생성하여 이용함으로서 객체에 대한 접근 단순화
-
DBA가
PUBLIC SYNONYM을 생성, 삭제 하며 모든 사용자가 접근 가능한 Synonym 생성CREATE SYNONYM kd_emp FOR kdhong.emp; CREATE SYNONYM ex_emp FOR excellent_employee_table; CREATE PUBLIC SYNONYM emp FOR jhh.emp; DROP SYNONYM kd_emp;
시퀀스(Sequence)
- 자동으로 유일한(Unique) 순차 값을 생성하는 DB 객체
- 기본 키 (Primary key) 값 생성 시 주로 사용
- 메모리 Cache시 시퀀스 값에 대한 접근 효율 증가
- 다른 사용자에게 공유 가능
-
시퀀스 정보는
user_sequences데이터 사전 뷰에 저장 -
시퀀스 생성
CREATE SEQUENCE sequence_name [ INCREMENT BY n ] [ START WITH n ] [ MAXVALUE n | NOMAXVALUE ] [ MINVALUE n | NOMINVALUE ] [ CYCLE | NOCYCLE ] [ CACHE n | NOCACHE ]START WITH: 시퀀스 시작 값. 기본 값은 1.CYCLE옵션 사용 시, 다시 값 생성할 때MINVALUE부터 시작INCREMENT BY: 시퀀스 증가 값. 기본 값은 1MAXVALUE n | NOMAXVALUE: 시퀀스의 최댓값. NOMAXVALUE 혹은 기본값일 경우 오름차순 $10^{27}$까지 커지고, 내림차순 1까지 작아질 수 있음MINVALUE n | NOMINVALUE: 시퀀스의 최소값. 기본값은 1. 오름차순 최소 1까지, 내림차순 $-10^{26}$까지 가능CYCLE | NOCYCLE: 최대 혹은 최소 값 달성 후 값을 다시 생성. 기본값은 NOCYCLECACHE n | NOCACHE: 빠른 접근을 위해 시퀀스 값을 메모리에 저장. 기본값은 20. NOCACHE일 경우 캐싱안함.CYCLE일 경우 한 사이클보다 작은 값을CACHE에 지정해야함
CREATE SEQUENCE emp_seq INCREMENT BY 10 START WITH 10 MAXVALUE 100000 NOCACHE NOCYCLE; INSERT INTO emp(empno, ename, deptno) VALUE(emp_seq.NEXTVAL, 'Kim', 2);sequence_name.NEXTVAL로 자동으로 다음 값 반환sequence_name.CURRVAL로 현재 값을 반환. 시퀀스 생성 후 바로CURVAL를 부르면 오류
SELECT emp_seq.CURRVAL FROM DUAL; SELECT emp_seq.NEXTVAL FROM DUAL; - 시퀀스 변경
ALTER구문으로 시퀀스 변경 가능START WITH은 변경이 불가능하며, 변경하고 싶으면 새로운 시퀀스 생성- 이후에 부여될 시퀀스 값만 변경
ALTER SEQUENCE sequence_name [ INCREMENT BY n ] [ MAXVALUE n | NOMAXVALUE ] [ MINVALUE n | NOMINVALUE ] [ CYCLE | NOCYCLE ] [ CACHE n | NOCACHE ] - 시퀀스 삭제 / 정보 확인
-
시퀀스 삭제
DROP SEQUENCE sequence_name; -
시퀀스 정보 확인
user_sequences: 사용자가 만든 시퀀스 정보dba_sequences: DB에서 설정된 시퀀스 정보
SELECT sequence_name, min_value, max_value, increment_by, last_number FROM user_sequences;
-
기타
SQL Injection
응용 프로그램 보안 상 허점을 이용해 의도적으로 악의적인 SQL문을 실행하여 DB를 비정상적으로 조작하는 방법이 SQL Injection이다.
DB Connection Pool (DBCP)
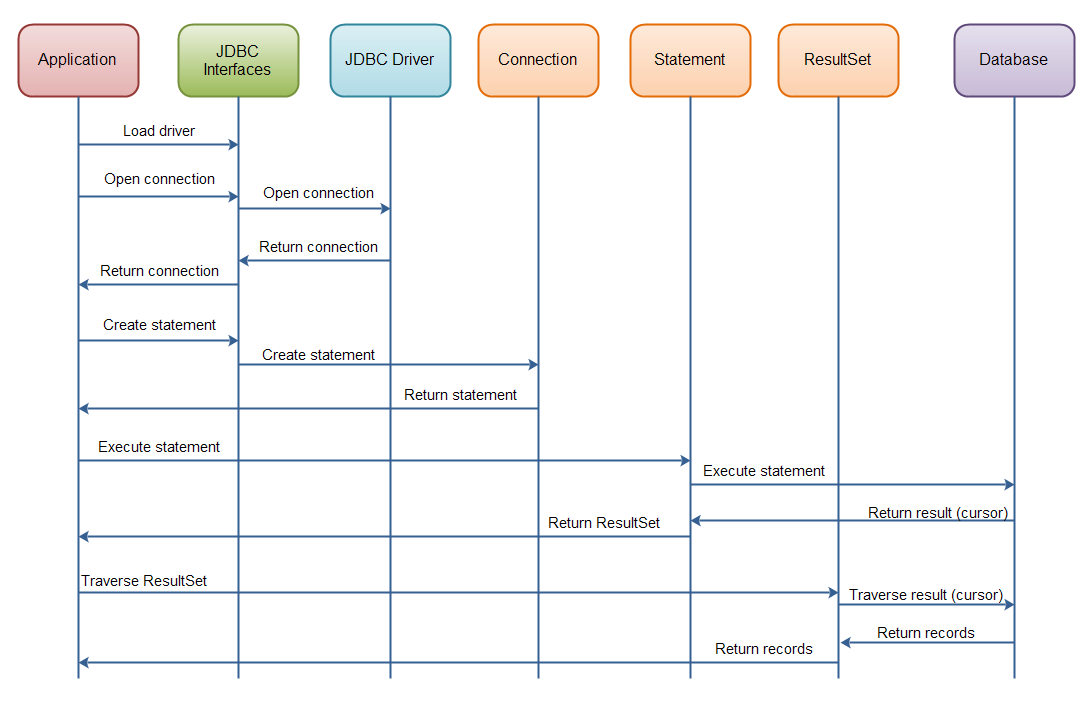
holaxprogramming 참고 DB에 연결하고 접속을 끊는 과정은 코스트가 크기 때문에, 미리 Connection Pool을 만들어두고 접속과 해제를 한다. JDBC의 경우 아래 과정을 Connection시 거친다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
try {
Connection connection = DriverManager.getConnection(address, uuserName, password);
PreparedStatement ps = connection.prepareStatement(query);
ps.setString(1, id);
ResultSet rs = get.executeQuery();
...;
}
catch (Exception e) {
}
finally {
rs.close();
ps.close();
}
- JDBC 드라이버를 로드한다.
- DriverManager.getConnection() 함수를 통해 DB Connection 객체를 얻는다.
- Connection 객체로 부터 쿼리를 수행하기 위한 PreparedStatement 객체를 얻는다.
- executeQuery 문을 수행하여 결과로 ResultSet 객체를 받아서 데이터를 처리한다.
- 처리가 완료되면 처리에 사용된 리소스들을 close하여 반환한다.
만약 위와 같이 연결이 생성될 때마다 드라이버를 로드하고, Connection 객체를 연결한다면 물리적인 DB 서버에 계속해서 연결해야하므로 비용이 크다. 그래서 DB Connection Pool을 만들어 이 문제를 완화한다.
Connection Pool
- WAS(Web Application Server)가 실행되면 미리 DB Connection 객체들을 여러개 생성해두고
Pool에 저장해둔다. - 연결 필요시 Pool에서 Connection 객체를 가져다 쓰고 반환한다.
- 위의 두 과정을 통해 Connection 객체를 생성하는 비용이 줄어들게된다.
JDBC
DB에 접근을 용이하도록 Java가 제공하는 API
- 관계형데이터베이스에 사용되는 SQL문을 실행하기 위해 자바로 작성된 클래스와 인터페이스로 구성된다.
- 특정 DB나 DB 매커니즘에 구애 받지 않는 독립적인 인터페이스를 통해 다양한 DB에 접근이 용이하다.
java.sql,javax.sql패키지에 포함되어 있다.
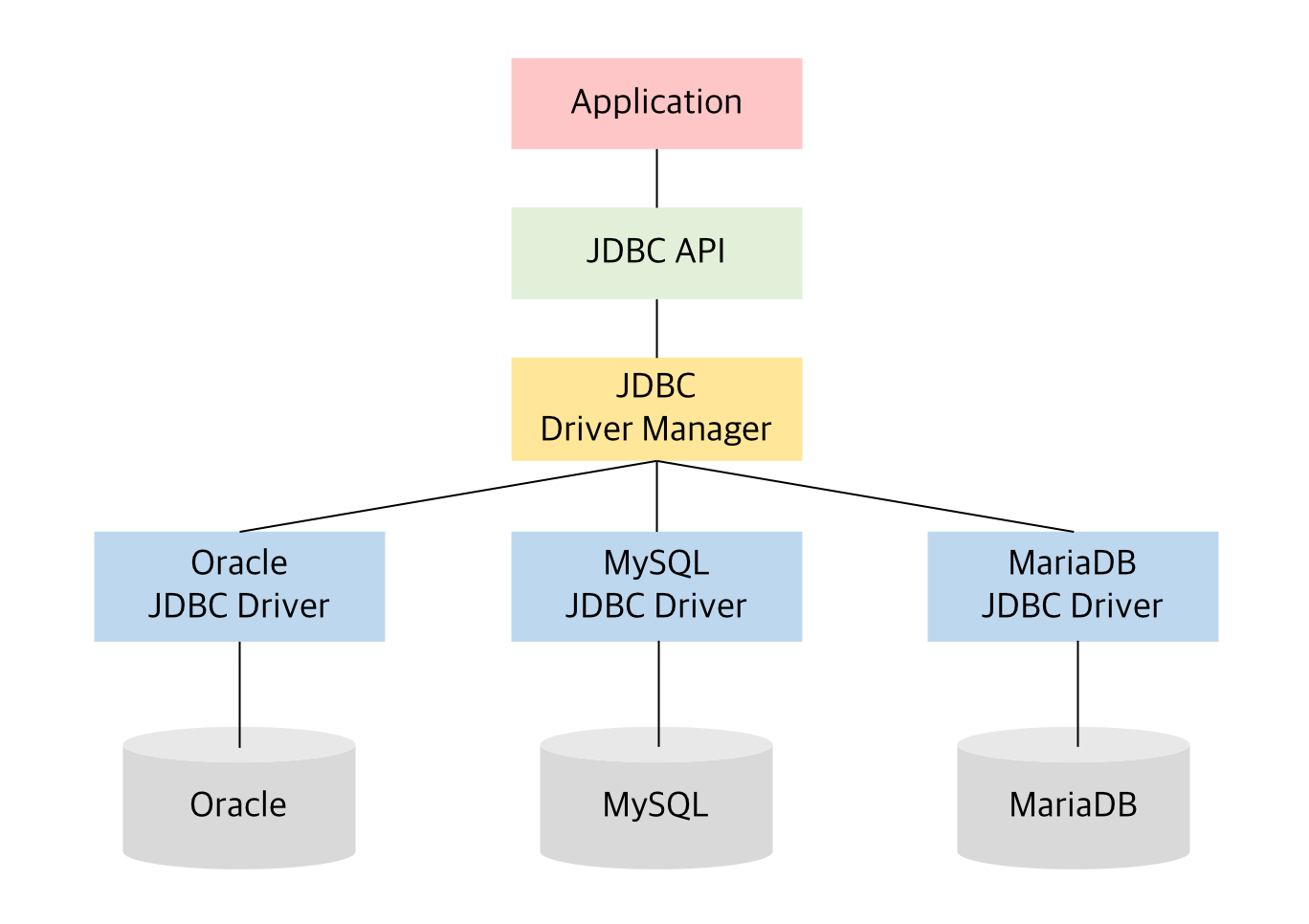
JDBC를 이용한 DB 접근 순서
1. JDBC driver 로딩
- JDBC driver : 자바 프로그램의 요청을 DBMS가 이해할 수 있는 프로토콜로 변환해주는 클라이언트 사이드 어뎁터 *
1
2
Class.forName("oracle.jdbc.driver.OracleDriver");
2. Connection
1
2
conn = DriverManager.getConnection(url, user, pass);
3. SQL 실행
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Statement stmt = conn.createStatement();
query = "SELECT table_name FROM " +
"user_tables";
ResultSet rs = stmt.executeQuery(query);
while (rs.next())
{
String name = rs.getString("table_name");
tableNames.add(name);
}
rs.close();
stmt.close();
conn.commit();
conn.close();
ORM
Object-Relational Mapping (객체 관계 맵핑)
- 객체와 관계형 DB의 데이터를 자동으로 맵핑 해줌
Persistence (영속성)
- 프로그램이 종료되더라도 데이터는 사라지지 않는 특성
- 프로그램 상에서 만들어진 데이터는 메모리 위에 있어 프로그램이 종료되면 없어지게 된다. 이를 파일 시스템, 관계형 테이터베이스, 객체 데이터 베이스 등을 활용하여 데이터를 영구하게 저장해 영속성을 부여할 수 있다.
Persistent Framework
JDBC 프로그래밍의 복잡합, 번거러움 없이 간단한 작업만으로 DB와 연동되는 시스템을 빠르게 개발 가능하며, 안정적인 구동을 보장한다.
- SQL 문장으로 직접 DB 데이터를 다루는 SQL 맵퍼
- Mybatis 등
- 객체를 통해 간접적으로 DB 데이터를 다루는 객체 관계 맵퍼 (ORM)
- Hibernate, JPA
- 스프링 프레임워크는 기본적으로 JPA 지원
- JDBC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public String getPersonName(long personId) throws SQLException {
PreparedStatement st = null;
try {
st = connection.prepareStatement (
"SELECT name FROM people WHERE id = ?");
st.setLong(1, personId);
ResultSet rs = st.excuteQuery();
if (ts.next()) {
String result = rs.getString("name");
assert !rs.next();
return result;
} else {
return null;
}
} finally {
if (st != null) {
st.close();
}
}
}
- JPA
1
2
3
4
5
public String getPersonName(long personId) {
Person p = em.find(Person.calss, personId);
return p.getName();
}
ORM의 장점
- 객체 지향적인 코드를 사용해 더 직관적이고 비즈니스 로직에 집중해 개발이 가능하다.
- 선언문, 할당, 종료 같은 부수적인 코드가 급격히 줄어듬
- 각종 객체에 대한 코드를 별개로 작성해 가독성 상승
- SQL의 절차적이고 순차적인 접근이 아닌 객체 지향적인 접근으로 생산성 증가
- 재사용 및 유지보수 편리성 증가
- DBMS에 대한 종속성 감소
ORM의 단점
- 설계를 신중하게 해야함
- 일부 쿼리의 경우 튜닝이 필요함
- DBMS 고유의 기능 활용 힘듬
- 프로시져가 많은 시스템에선 ORM의 객체 지향 장점을 활용하기 어려움
NoSQL
Not Only SQL의 준말로 보통 사용되고 있으며, 기존 관계형 DBMS가 관계를 중점으로 ACID를 지켜 시스템이 짜여 졌다면, NoSQL에서는 관계형 데이터 모델을 지양하고 대량의 분산된 데이터베이스를 저장하고 조회하는데 특화된 느슨한 스키마를 제공하는 저장소를 의미한다. RDBMS의 ACID 이론과 다르게 CAP이론을 따른다.
- 기존의 관계형, 정형 데이터가 아닌 비정형 데이터를 쉽게 저장하고 처리하기 위한 저장소
- 기존 RDBMS 보다 더 융통성 있는 데이터 모델을 사용하고, 데이터 저장 및 검색을 위한 특화된 매커니즘 제공
- 응답 속도, 처리 효율이 기존 RDBMS 보다 뛰어남
- 관계형 모델을 사용하지 않고, 테이블간 조인이 없음
- 직접 프로그래밍 등 비 SQL 인터페이스를 통해 데이터 엑세스
- 여러 대의 DB 서버를 묶어 (클러스터링) 하나의 DB 구성
- ACID 미보장
- 데이터 스키마와 속성들을 다양하게 수용하고 동적으로 정의가 가능함 (Schema-less)
- 확장성, 가용성, 높은 성능
- 중단 없는 서비스, 자동 복구 기능 지원
- Open Source로 많이 존재
CAP 이론
1. Consistency (일관성) ACID의 C와 유사하다. 다중 클라이언트에게 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것을 의미한다. 이는 데이터 일관성이 NoSQL에서는 느슨하게 처리되기 때문에 나타나는데, 이 때문에 데이터가 시간에 따라 여러 노드에 전파되고 클라이언트가 받는 데이터가 일정하지 않을 수 있다. 이를 위해 두 가지 동기화 방법을 사용한다. 첫번째로 저장 결과를 클라이언트에게 응답하기 전 모든 노드에 데이터를 저장하는 느린 방식과, 두번째로 메모리나 임시 파일에 데이터를 먼저 기록하고 클라이언트에게 우선 응답한 후 각 노드로 데이터를 동기화하는 비동기식 방법이 있다. 두번째 방법은 응답속도는 빠르지만 데이터 손실이 나타날 수 있다.
2. Availability (가용성) 모든 클라이언트의 읽기와 쓰기 요청에 항상 응답 가능한 상태여야한다. 이런 NoSQL들은 몇 개의 노드가 망가져도 정상적인 서비스가 가능하다. 하둡과 같이 같은 데이터를 복제하여 사용하는 방법이 있다.
3. Partition Tolerance (네트워크 분할 허용성) 지역적으로 분할된 네트워크 환경에서 두 네트워크가 단절되거나, 네트워크 데이터 유실이 일어나더라도 각 네트워크의 시스템은 정상적으로 작동되어야한다.
NoSQL 분류
1. Key-Value Model 기본적인 형태의 NoSQL 키 하나로 데이터 하나를 저장하고 조회할 수 있는 단일 키-값 구조를 가진다. 복잡한 조회 연산을 하지 않고, 고속 읽기와 쓰기에 최적화된 경우가 많다. 다수의 데이터 조회 및 수정 연산이 일어나면 트랜젝션 처리가 어려우 데이터 정합성(Integrify) 보장이 어렵다. 세션, 장바구니 등의 정보 저장 시 사용한다.
2. Document Model 키-값 모델을 개념적으로 확장한 구조로 하나의 키에 하나의 구조화된 문서를 저장하고 조회한다. 노리적인 데이터 저장과 조회 방법이 관계형 DB와 유사하다. 키는 각 문서에 대한 ID 이며, ID에 대한 인덱스를 문서 생성 시 생성한다. 문서를 컬렉션으로 관리하며, ID에 인덱싱을해 O(1) 시간 만에 문서 조회가 가능하다. 보통 B 트리를 통해 인덱싱을 하며 2차 인덱스를 사용한다. 이 때문에 트리가 너무 커지면 새로운 데이터 입력 및 삭제 시간이 늘어나 성능이 떨어지므로 보통 읽기 쓰기 비율이 7:3 일 때 이상적이다. 로그, 타임라인, 통계 정보 등의 저장에 사용된다.
3. Column Model 하나의 키에 여러 개의 컴럼 이름과 컬럼 값의 쌍으로 이루어진 데이터를 저장하고 조회한다. 모든 컬럼은 타임 스탬프와 함께 저장된다. 구글의 빅테이블이 대표적인 예시고, 이후 NoSQL은 빅테이블에 영향을 받았다. Row Key, Column Key, Column Family와 같은 빅테이블 개념이 공통적으로 사용된다. 대부분 Column Model은 쓰기에 더 틍화되어 있다. 데이터를 먼저 커밋 로그와 메모리에 저장한 후 응답하기 때문에 빠른 응답 속도를 제공한다. 빠른 시간안에 대량의 데이터 입력 및 조회하는 서비스 구현 시 성능이 가장 좋다. 하둡 또한 Column Model을 사용한다. Key space는 Column Family들을 포함한다.
4. Graph Database 데이터를 노드로 표현한다. 각 노드가 데이터가 되고, 각 노드 사이의 관계를 엣지로 표현한다.